
Concurrency vs Parallelism

如果你看看今天的编程语言,可能会发现这个世界是面向对象的,但实际上并非如此,世界是并行的。你通过网络等等,从最底层(例如:多核计算机)获取所有的东西,一路攀升到了解星球、宇宙。世界上所有的东西都在同时发生,但我们拥有的计算工具实际上并不擅长表达这种世界观。看起来似乎是一种失败,如果我们了解什么是并发性,以及如何使用它,就可以解决这个问题。

我将假设你们中的大多数人至少听说过 Go 编程语言,它也是我最近几年在 Google 工作的内容。Go 是一种并发语言,也就是说它使并发性有用,有像上帝一样同时执行事物的能力;有在同时执行的事物之间进行通信的能力;有叫做 select 语句的东西,它是一个多路并发控制开关。如果你搞不懂是怎么回事,不用担心。

在大约两年前,当我们发布 Go 时,在场的程序员都说:”哦,并发工具,我知道做什么的,并行运行,耶“。但实际并非如此,并发性和并行性是不一样的,这是个常被误解的问题。我在这里试图解释原因,并向您展示并发性实际上更好。那些困惑的人会碰到什么事情:他们执行的程序,在更多的处理器上会变得更慢。他们会认为有问题,不管用,想要逃开。但真正有问题的是世界观,我希望我能改正它。

什么是并发性?并发性,如我当前使用的一样,用于计算机科学领域,是一种构建事物的方法。它是由独立执行的事物组成,通常是 function,虽然不一定必须如此。我们通常称之为交互式进程。称其为进程,并不是指 Linux 进程,指的是一种普遍的概念,它包括线程、协程、进程等等,所以尽可能抽象的理解。并发性由独立执行的进程组成;

另一方面,并行性是同时执行多个事物,可能相关,也可能无关。

如果你用语焉不详的方式思考,并发性是指同时负责很多事情;并行性是指同时做很多事情。它们显然是相关的,但实际上是不同的概念,如果没有合适的工具包,尝试思考它们会有些困惑。一个是关于结构并发性,另一个是关于执行并行性。我会告诉你为什么这些概念很重要。并发性是一种构造事物的方法,以便可以使用并行性更好地完成工作。但并行性不是并发性的目标,并发性的目标是好的结构。
An analogy

如果你在运行一个操作系统的话,会很熟悉的一个类比。操作系统可能有鼠标驱动程序、键盘驱动程序、显示驱动程序、网络驱动程序等等,都是由操作系统管理的,内核中的独立事物。它们都是并发的事物,却不一定是并行的。如果只有一个处理器,同一时间其中只有一个处于运行。I/O 设备具有一个并发模型,但本质不是并行的,它不需要是并行的。并行的事物可能类似向量点积,可以分解为微观操作,以使得可以在一些精美的计算机上并行执行。非常不同的概念,完全不是同一个东西。
Cocurrency plus communication

为了能利用并发性,必须添加 communication 的概念。我今天不会聚焦于该概念太多,但一会儿你会看到一点点。并发性提供了一种将程序构造为独立块的方法,然后,必须使这些块协调一致。要使之工作,需要某种形式的 communication。Tony Hoare 在1978年写了一篇论文叫做 《communicating sequential processes》,实在是计算机科学中最伟大的论文之一。如果你还没读过,要是从本次演讲中真有什么领悟的话,回家你应该读读那篇论文。它太不可思议了,基于此论文,很多人未进行太多考虑就遵循、并构建工具,以将其思想运用到并发语言中,比如另一种很棒的语言Erlang。GO 中也有其一些思想,关键点都在原稿中,除了稍后会提到的几个小例外。
Gophers

但,你看这一切太抽象了。我们需要 Gopher 的帮忙,来一些 Gopher。
有一个真正的问题我们要解决。有一堆过时的手册,可以是 C++98 手册,现在已经是 C++11;或许是 C++11 书籍,但不再需要了。关键是我们想要清理掉它们,它们占用了大量空间。所以我们的 Gopher 有一个任务,把书从书堆里取出来,放到焚化炉里清理掉。但是,如果是一大堆书,只有一个 Gopher 需要很长时间。Gopher 也不擅长搬运书籍,尽管我们提供了小车。

所以再增加一个 Gopher 来解决这个问题,只有 Gopher 不会好起来,对吧?
因为它需要工具,无可厚非,我们需要提供所有它需要的东西。Gopher 不仅需要作为 Gopher 的能力,也需要工具来完成任务。再给它一辆车,现在这样应该会更快。在两个 Gopher 推车的情况下,肯定能更快地搬运书。但可能存在一个小问题,因为我们必须使它们同步。来回奔波中,书堆互相妨碍,它们可能会被困在焚化炉里,所以它们需要协调一点。所以你可以想象 Gopher 们发送 Tony Hoare 的短信息,说:我到了,我需要空间把书放进焚化炉。不管是什么,但你明白了,这很傻。但我想解释清楚,这些概念并不深刻,它们非常好。
如何让它们搬运得更快,我们把一切都增加一倍。我们提供两个 Gopher,把书堆,焚化炉和 Gopher 一样也增加一倍。现在我们可以在相同的时间里搬运两倍的书,这是并行,对吧?
但是,想象它不是并行,而是两个 Gopher 的并发组合。并发性是我们表达问题的方式,两个 Gopher 可以做到这一点。我们通过实例化 Gopher 程序的更多实例来并行,这被称为进程(在此情况下称为 Gopher)的并发组合。

现在这种设计不是自动并行的。确实有两个 Gopher,但是谁说它们必须同时工作呢?我可以说,同时只有一个 Gopher 可以移动,就像单核计算机,此设计仍然是并发的,很好很正确,但它本质上不是并行的,除非让两个 Gopher 同时搬运。当并行出现时,有两个事物同时执行,而不仅仅是拥有两个事物。这是一个非常重要的模型,一旦断定理解了它,我们就会明白可以把问题分解成并发的块。
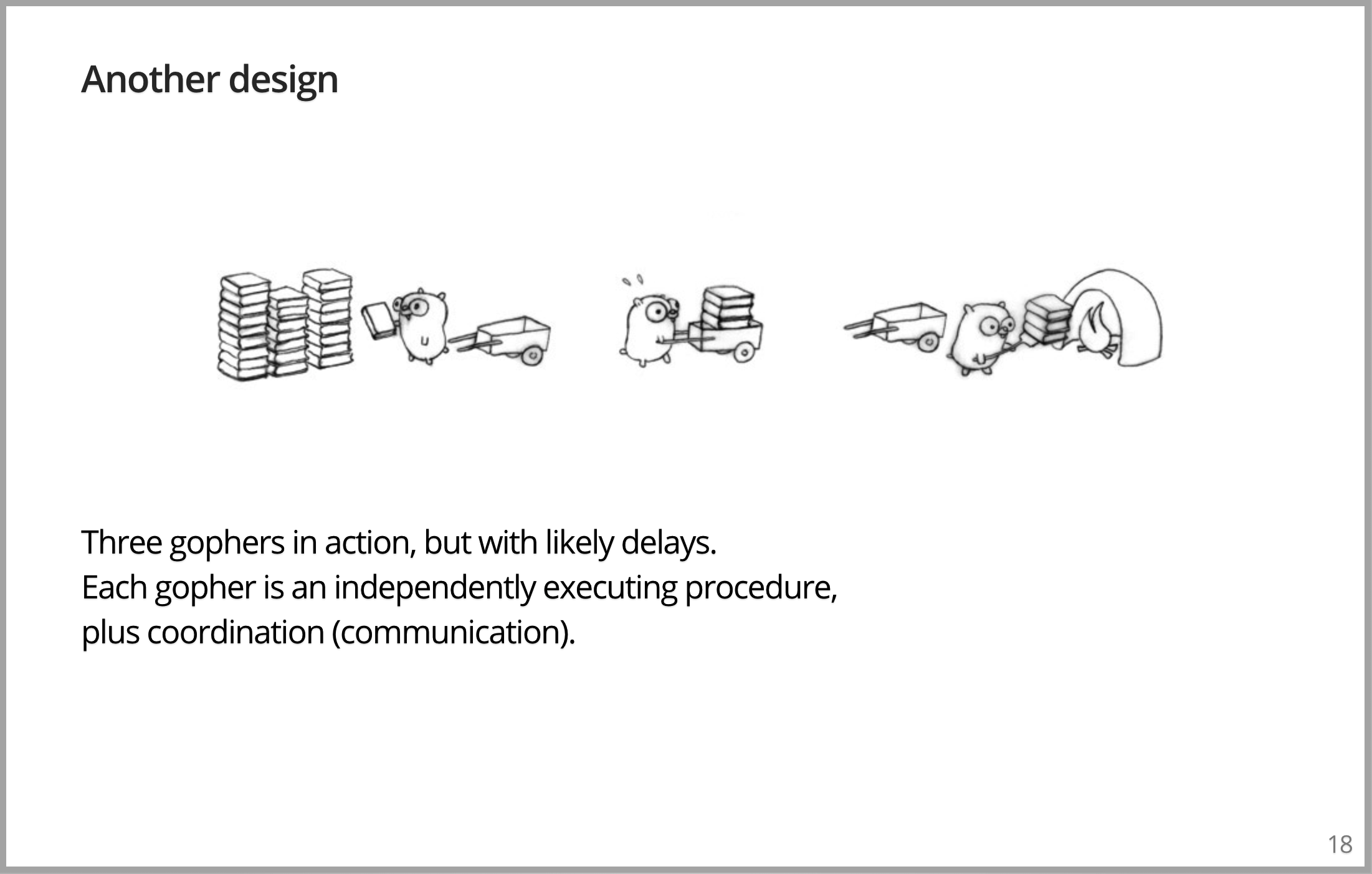
我们可以想出其他模型,下面有一个不同的设计。在图中有三个 Gopher,同一堆书,同一个焚化炉,但是现在有三个 Gopher。有一个 Gopher,它的工作就是装车;有一个 Gopher,它的工作就是推车,然后再把空的还回去;还有一个 Gopher,它的工作就是装入焚化炉。三个 Gopher,速度理应会更快。但可能不会快多少,因为它们会被阻塞。书可能在错误的地方,在那里没有什么需要用车来做的。
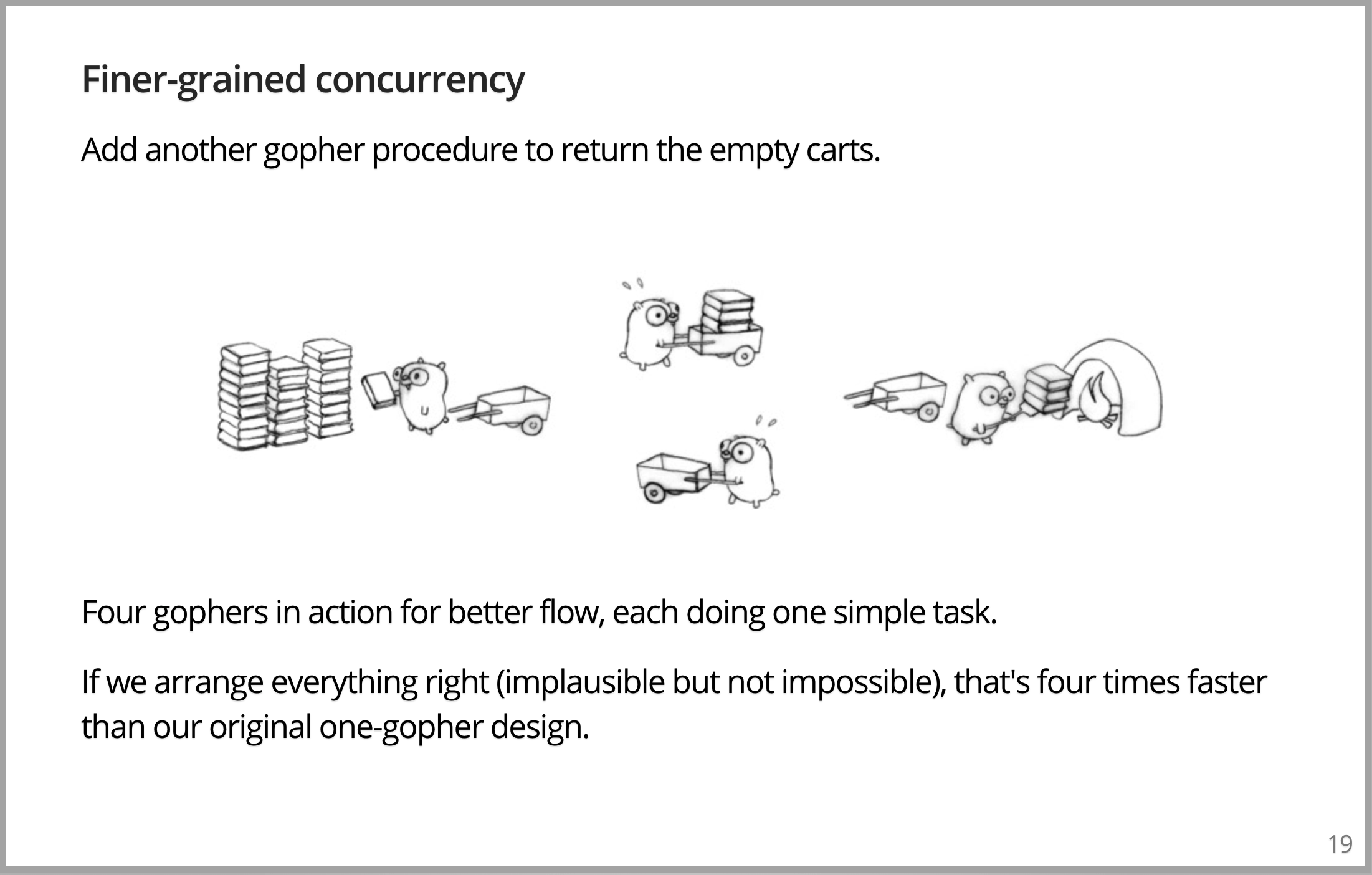
让我们处理下这个问题,另外增加一个Gopher归还空车,这明显很傻。但我想指出一个相当深刻的问题,这个版本的问题实际上会比之前版本的问题执行得更好。尽管为了完成更多的工作,增加了一个 Gopher 来回奔波。因此,一旦我们理解了并发性的概念,就可以向图片增加 Gopher,真的可以做更多的工作,使之运行得更快。因为管理的更好的块的并发组合真的可以运行得更快。工作可能不会恰好完美地进行,但是可以想象如果所有的 Gopher 的时间都恰到好处,它们知道每次搬运多少书。并发组合真的可以让4个 Gopher 都一直在忙碌。事实上,此版本可能比原来的版本快四倍。虽然可能性不大,但是我想让你理解,是可能的。

此时有一个发现,它非常重要而且很微妙,有些柔性。我们在现有的设计中通过添加并发程序来提高程序的性能。我们真的添加了更多的东西,整个过程变得更快了。如果仔细想想,有点奇怪,也有点不奇怪。因为额外添加了一个 Gopher,而且 Gopher 确实工作。但是如果你忘记了它是个 Gopher 的事实,并认为只是增加了东西,设计确实可以使它更高效。并行性可以出自于对问题更好的并发表达,这是一个相当深刻的见解。因为 Gopher 们的参与所以看起来不像。但是没关系。

此时有四个进程并发运行。一个 Gopher 将东西装到车中;一个 Gopher 把车运到焚化炉;还有另一个 Gopher 将车中的物品卸到焚化炉中;第四个 Gopher 把空车还回来。您可以将它们视为独立的进程,完全独立运行的进程,我们只是将它们并行组合以构建完整的程序解决方案。这不是我们唯一可以构造的方案,以下是一个完全不同的设计。
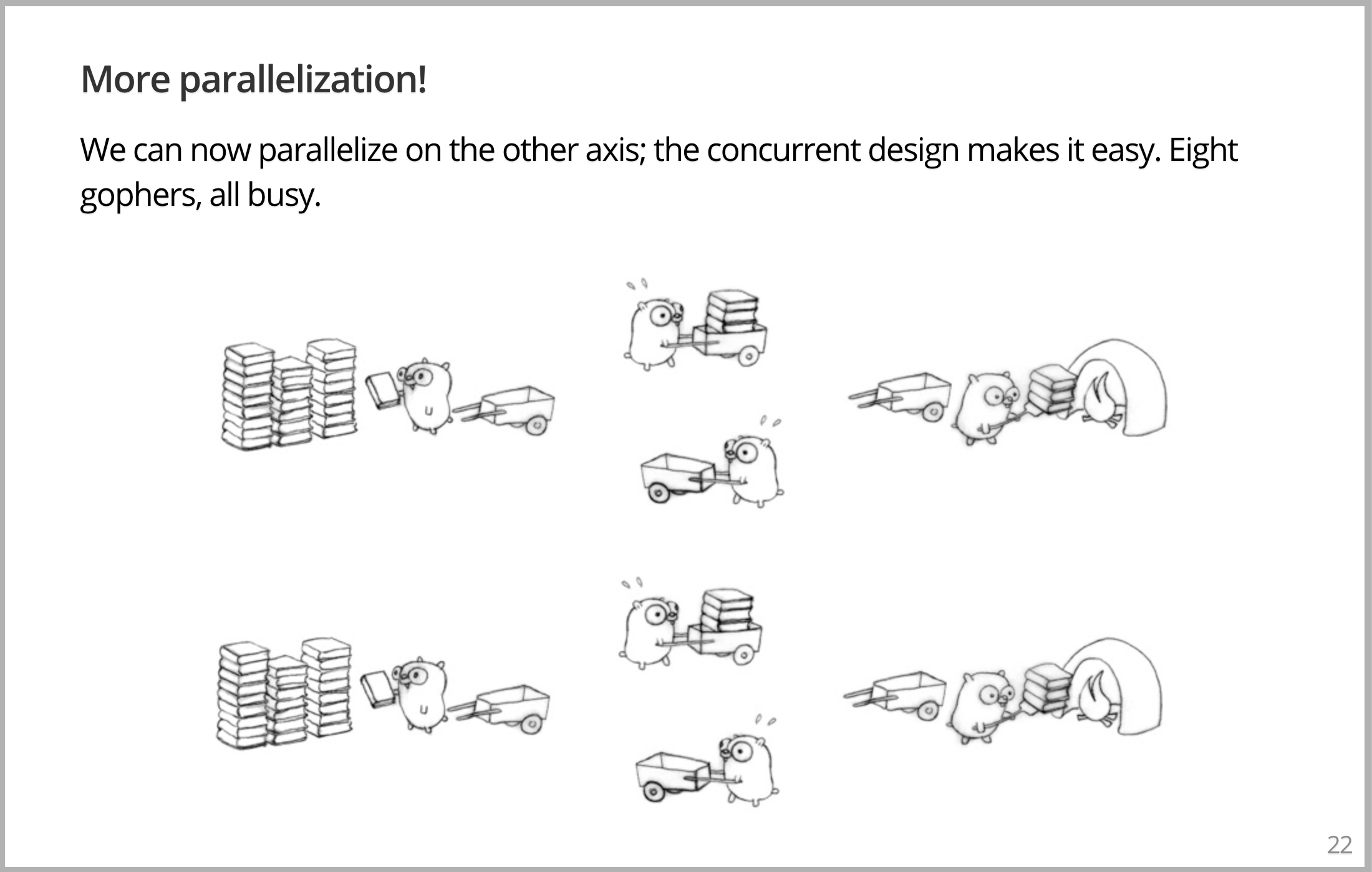
通过增加另外一个堆书、焚化炉、和4个 Gopher,可以使该设计更加并行。但关键是,采用已有概念以分解问题。一旦清楚这是并发分解,就可以在不同的纬度上使其并行化。无论能否获得更好的吞吐量,但是至少,我们得以更细粒度的理解问题,可以控制这些块。在此情况下,如果一切刚好,会有8个 Gopher 努力以烧掉那些C++手册。
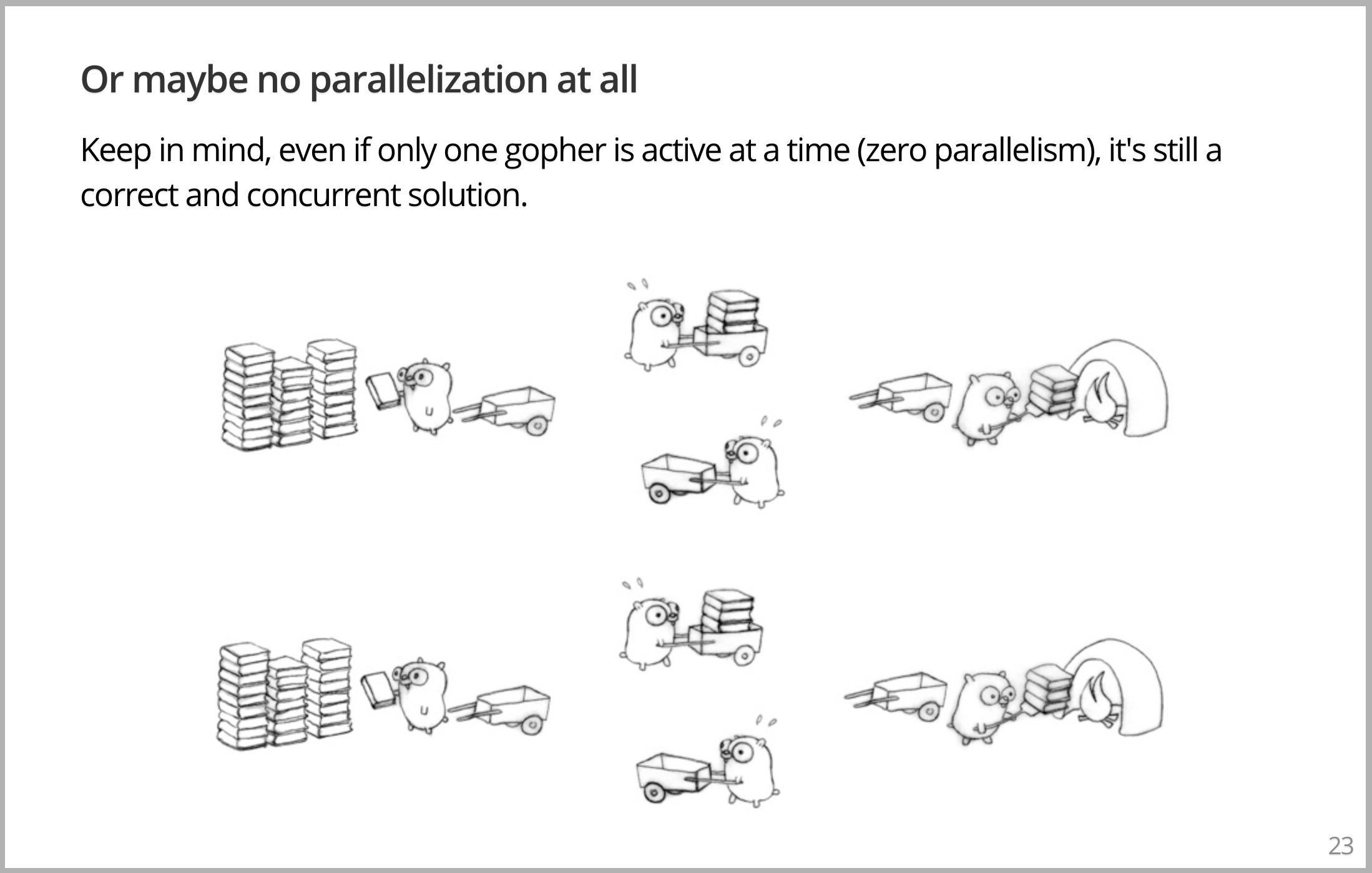
当然,也许根本没有发生并行,谁说这些 Gopher 必须同时工作,我可能每次只能运行一个 Gopher。在这种情况下,该设计只能像原始问题一样,以单个 Gopher 的速率运行。它执行时,其他7个将全部空闲。但该设计仍然是正确的。这很了不得,因为意味着我们在保证并发性时不必担心并行性。如果并发性正确,并行性实际上是一个自由变量,决定有多少个 Gopher 处于忙碌。我们可以为整个事情做一个完全不同的设计。
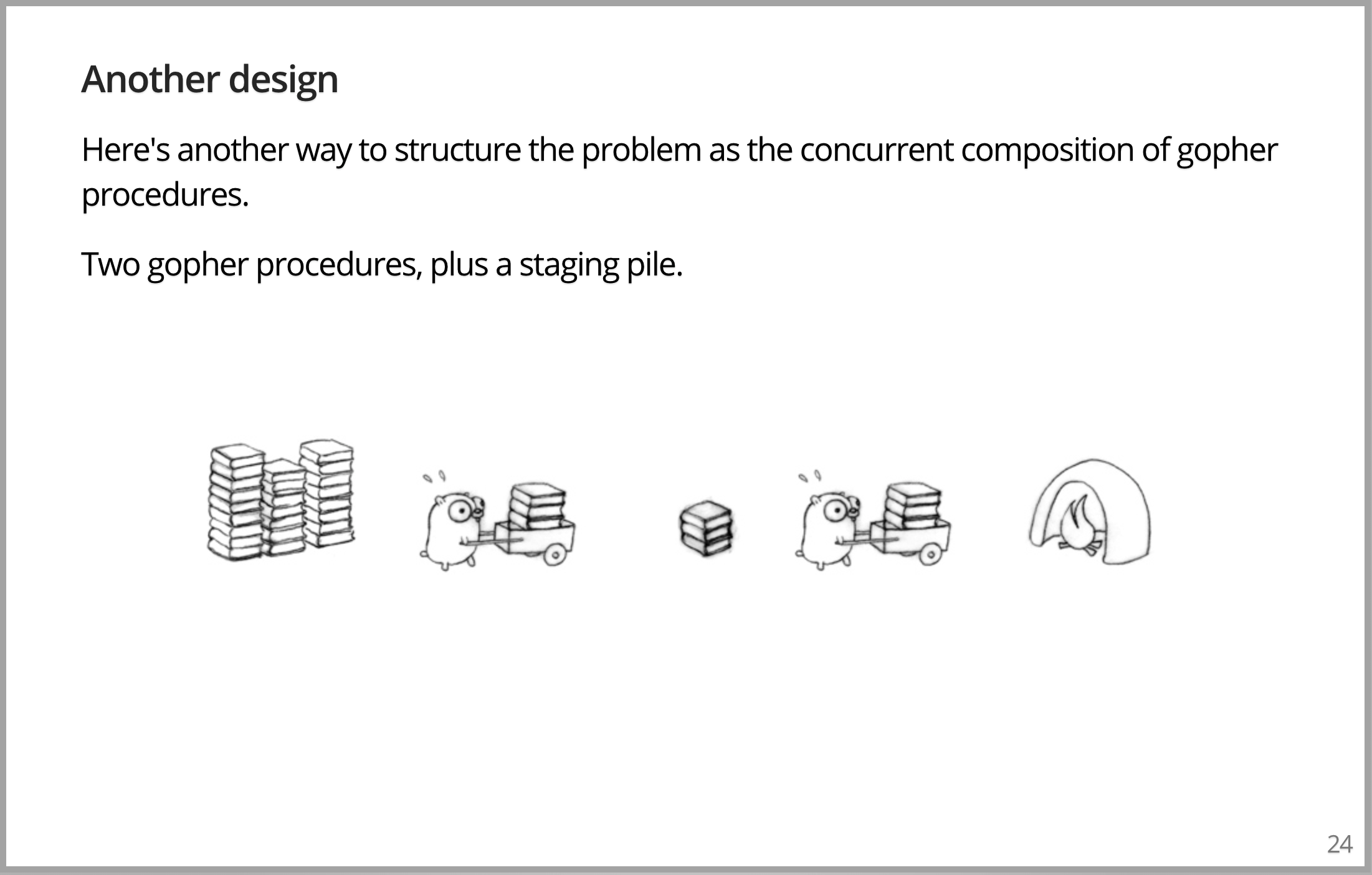
让我们忘记将旧模式投入到新模式。在故事中有两个 Gopher,不再让一个 Gopher 从书堆一直运到焚化炉,而是在中间加入暂存区。因此,第一个 Gopher 将书籍搬运到暂存区,将它们丢下,跑回去再运另外一些。第二个 Gopher 坐在那里等待书达到暂存区,并把书从该位置搬运到焚化炉。如果一切良好,则有两个 Gopher 进程运行。它们是相同的类型,但有些细微不同,参数略有不同。如果系统将正常运行,一旦启动,其运行速度就会是原始模式的两倍。即使某些方面说它是完全不同的设计。一旦我们有了这个组合,我们可以采取另外的做法。
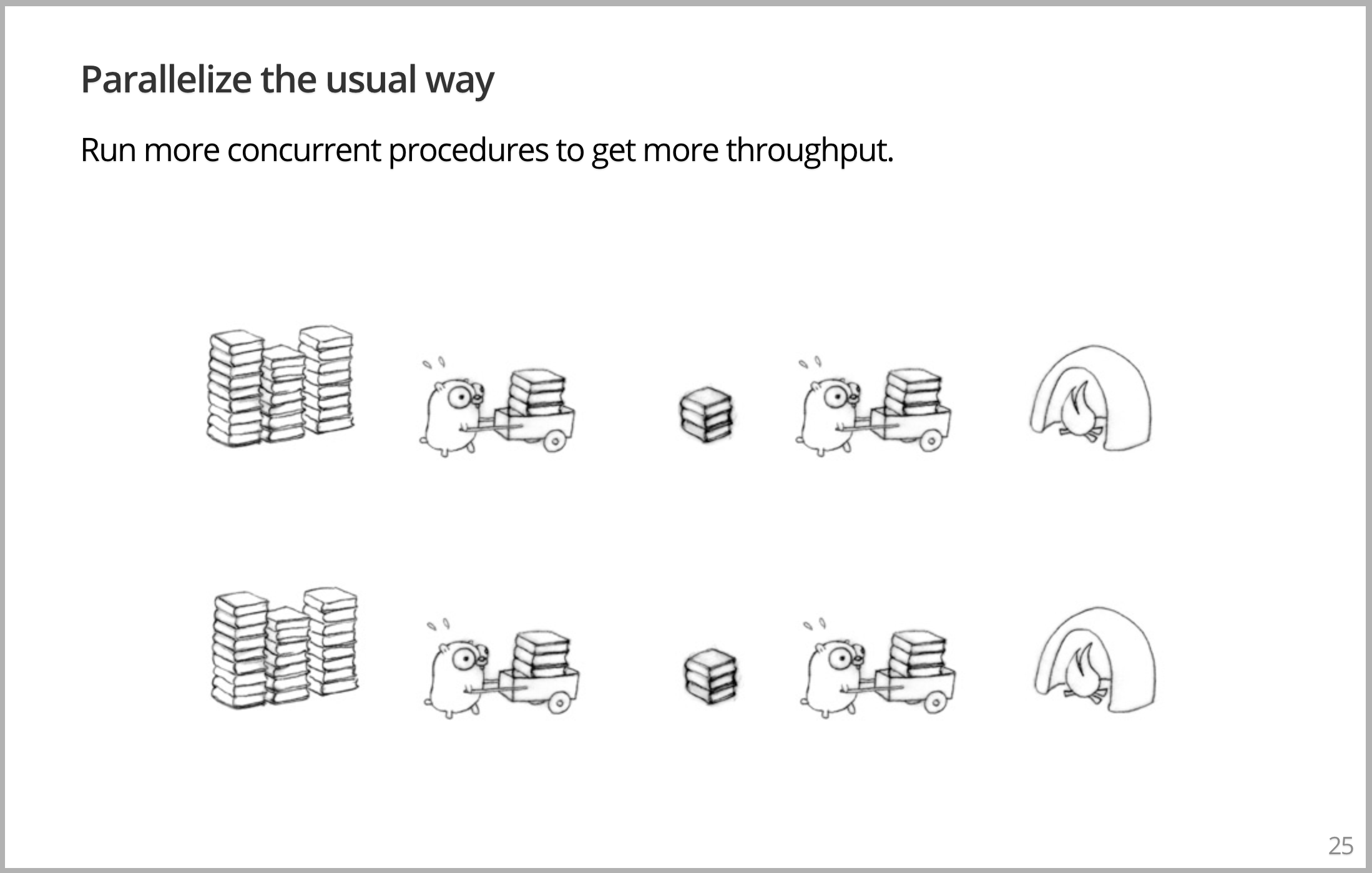
将以惯常的做法使其并行,同时运行整个程序的两个版本。翻倍之后,有了4个 Gopher,吞吐量将高达四倍。
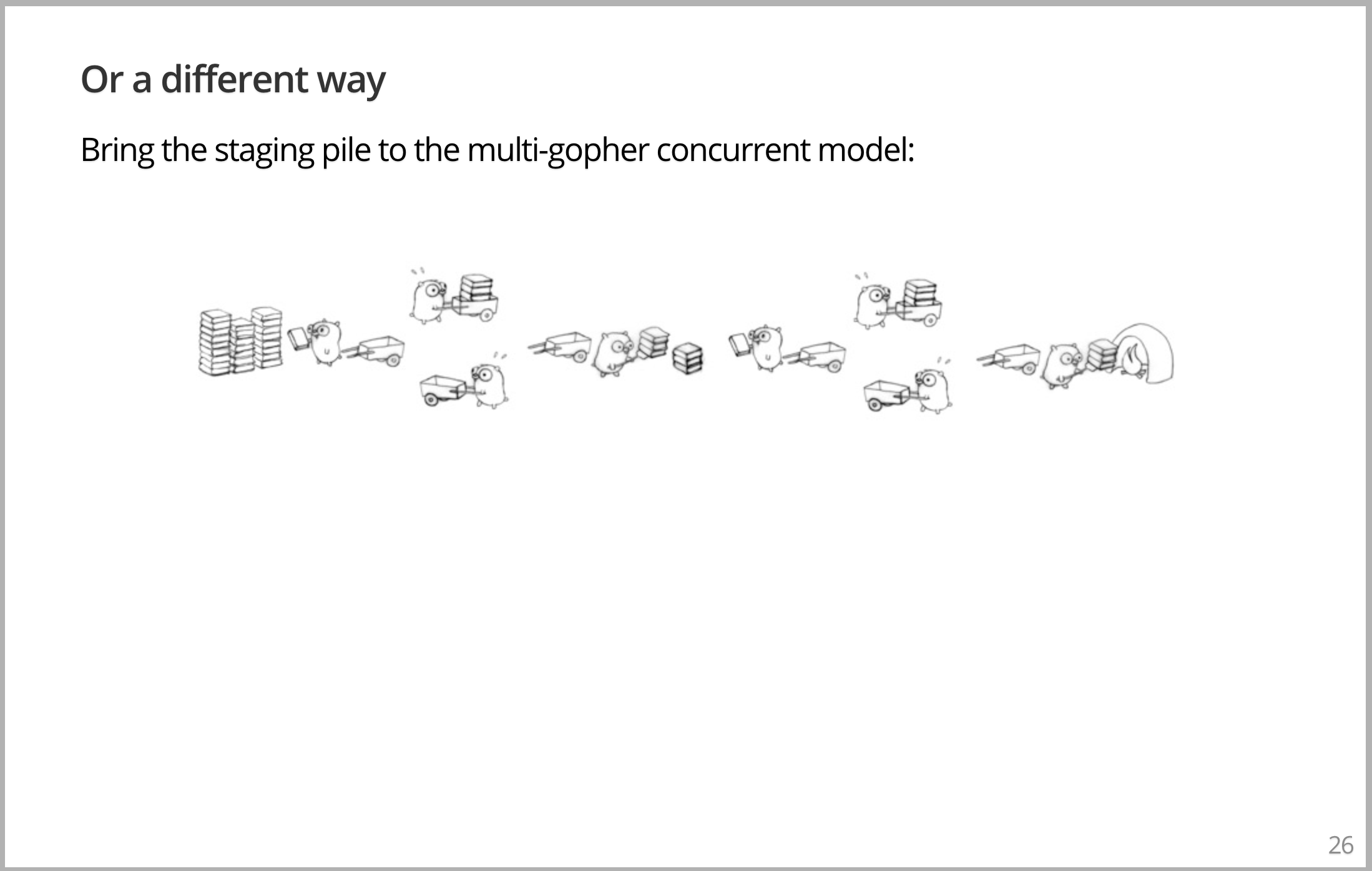
或者,我们可以采用另一种做法,在刚才的并发多 Gopher 问题中,在中间加入暂存区。因此,现在我们有8个 Gopher 在运行,书籍非常快的速度被焚烧。
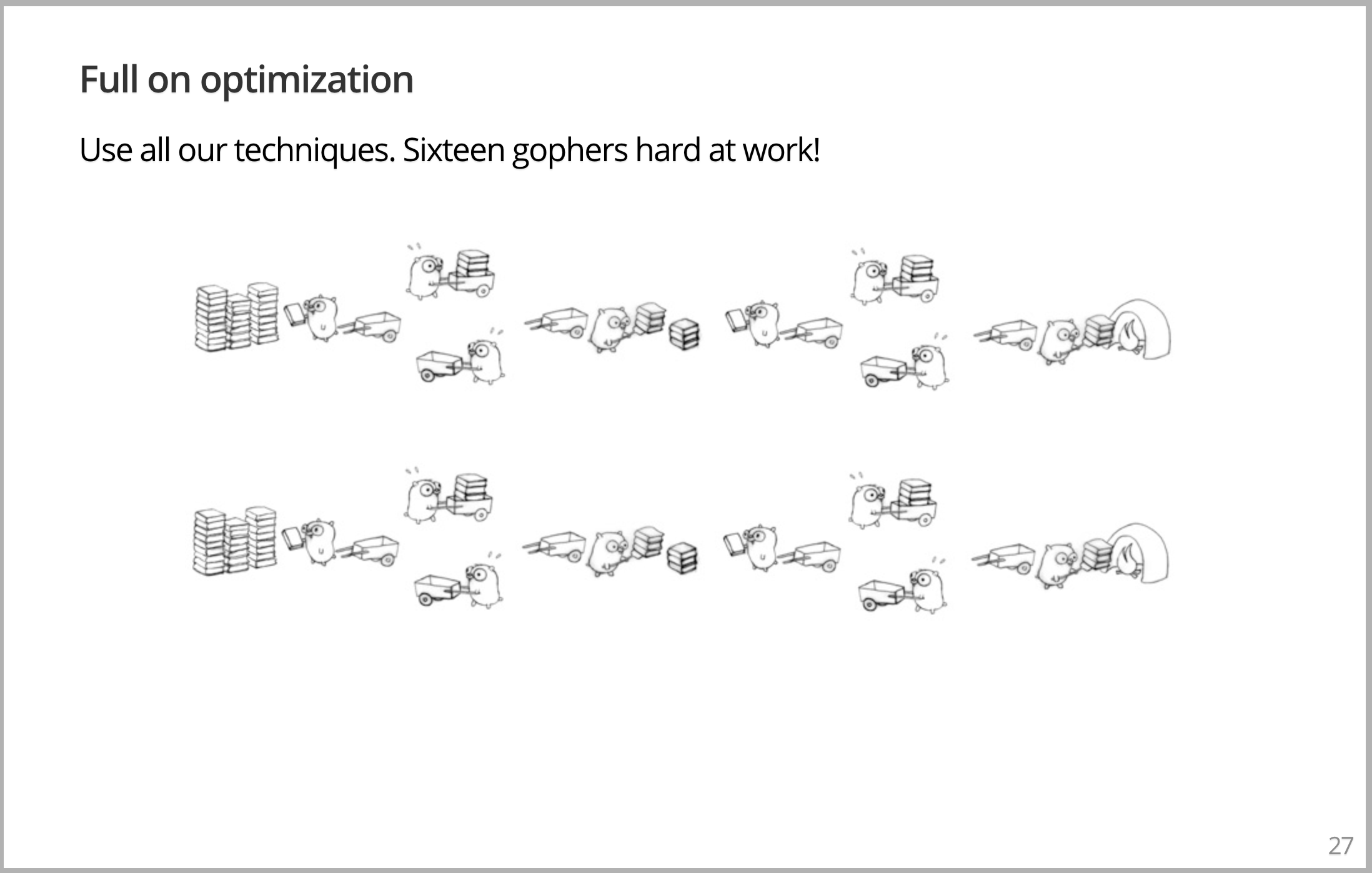
但这样还不够好,因为我们可以在另一个维度并行,运力全开。此时,有16个 Gopher 将这些书搬运到焚化炉中。显然,增加 Gopher 使问题解决的更好,是非常简单和愚蠢的。但我希望您了解,从概念上讲,这真的就是您考虑并行运行事物的方式。您无需考虑并行运行,而是考虑如何将问题以可分解、可理解、可操作的方式,分解为独立的块,然后组合起来以解决整个问题。
Lesson

以上就是的所有例子有什么意义呢?
首先,有很多方法可以做到这一点,我刚刚展示了一些。如果你坐在那里拿着一本速写册,你可能会想出另外50种让 Gopher 搬运书的方法。有很多不同的设计,它们不必都相同,但它们都能工作。然后,您可以对这些并发设计进行重构、重新排列、按不同的维度进行缩放,得到不同的功能以处理问题。真是太好了,因为不管你怎么做,处理这个问题的算法的正确性很容易保证。这样做不会搞砸,我的意思它们只是 Gopher,你知道这些设计本质上是安全的,因为你是那样做的。但是,这无疑是一个愚蠢的问题,与实际工作无关。嗯,事实上确实有关。

因为如果你拿到这个问题,把书堆换成一些网络内容;把 Gopher 换成 CPU,把推车换成网络或编码代码等等;把问题变成你需要移动数据;焚化炉是网络代理,或是浏览器,你想到的任何的数据使用者。您刚刚构建了一个 Web 服务体系结构的设计。你可能不认为你的 Web 服务架构是这样的,但事实上差不多就是这样。你可以把这两块替换掉看看,这正是你想的那种设计。当你谈论代理、转发代理和缓冲区之类会,扩容更多的实例的东西时,它们都在这个图上,只是不被这么想。本质上并不难理解它们,Gopher 能做到,我们也能。
A little background about Go
现在让我来展示如何在使用Go构建东西时采用这些概念。我不打算在这次演讲中教你 Go,希望你们有些人已经知道它,希望大家在之后能去更多了解它。但我要教一点点 Go,希望其他人也能像我们一样融入其中。
Goroutines

Go 有叫做 goroutine 的东西,可以认为有点像线程,但实际上是不同的。与其详细地谈有什么不同,不如说说它是什么吧。假设我们有一个函数,函数有两个参数。如果在程序中调用该函数 F,则在执行下一条语句之前要等待该函数完成。很熟悉,大家都知道。但是,如果在调用该函数之前放置关键字 go。你调用该函数,函数开始运行,虽然不一,至少在概念上可以立即继续运行。想想并发与并行,从概念上讲,当 F 不在时,程序一直在运行,你在做 F 的事情,不用等 F 回来。如果你觉得很困惑,那就把它想象成一个很像 shell 里的 & 符号。这就像在后台运行 F &,确切地说是一个 goroutine。

它有点像线程,因为一起运行在同一个地址空间中,至少在一个程序中如此。但 goroutine 要廉价得多,创建很容易,创建成本也很低。然后根据需要,goroutine 动态地多路映射到执行中的操作系统线程上,所以不必担心调度、阻塞等等,系统会帮你处理。当 goroutine 确实需要阻塞执行像 read 之类的系统调用时,其他 goroutine 不需要等待它,它们都是动态调度的。所以 goroutine 感觉像线程,却是更轻量版本的线程。这不是一个原始的概念,其他语言和系统已经实现了类似的东西。我们给它起了自己的名字来说明它是什么。所以称之为 goroutine。
Channels

刚刚已经提到需要在 goroutine 之间通信。为了做到这一点,在 Go 中,称之为 channel。它有点像 shell 中的管道,但它有类型,还有其他一些很棒的特性,今天就不深入了。但以下有一个相当小的例子。我们创建了一个timer channel,显然它是一个时间值的 channel;然后在后台启动这个函数;sleep 一定的时间 deltaT,然后在 timer channel 上发送当时的时间 time.now()。因为此函数是用 go 语句启动的,不需要等待它。它可以做任何想做的事情,当需要知道其他 goroutine 完成时,它说我想从 timer channel 接收那个值。该 goroutine 会阻塞直到有一个值被传递过来。一旦完成,它将设置为得到的时间,即其他 goroutine 完成的时间。小例子,但你需要的一切都在那张小幻灯片里。
Select

最后一部分叫做 select。它让你可以通过同时监听多个 channel 控制程序的行为。一旦就能看出谁准备好通信了,你就可以读取。在这种情况下,channel 1 或 channel 2,程序的行为将不同,取决于 channel 1 或 channel 2 是否准备就绪。在这种情况下,如果两个都没有准备好,那么 default 子句将运行,这意味着,如果没有人准备好进行通信,那么你会 fall through。如果 default 子句不存在,执行 select,需要等待其中一个或另一个 channel 就绪。如果它们都准备好了,系统会随机挑选一个。所以这种要晚一点才能结束。像 switch 语句,但用于通信场景。如果你知道 Dijkstra 的监督命令,应该会很熟悉

当我说 Go 支持并发,是说它确实支持并发,在 Go 程序中创建数千个 goroutine 是常规操作。我们曾经在会议现场调试一个go程序,它运行在生产环境,已经创建了130万个 goroutine,并且在调试它的时候,有1万个活跃的。当然,要做到如此,goroutine 必须比线程廉价得多,这是重点。goroutine 不是免费的,涉及到内存分配,但不多。它们根据需要增长和缩小,而且管理得很好。它们非常廉价,你可以认为和 Gopher 一样廉价。
Closures

你还需要闭包,我刚在前面的页面展示过闭包,这只是在 Go 语言中可以使用它的证据。因为它们是非常方便的并发表达式,可以创建匿名的 procedure。因此,您可以创建一个函数,在本例中,组合多个函数返回一个函数。这只是一个有效的证明,它是真正的闭包,可以使用 go 语句运行。

让我们使用这些元素来构建一些示例。我希望你能潜移默化的学习一些 Go 并发编程,这是最好的学习方法。
Some examples
Launching daemons

从启动一个守护进程开始,您可以使用闭包来包装一些您希望完成但不想等待的后台操作。在这种情况下,我们有两个 channel 输入和输出,无论出于什么原因,我们需要将输入传递到输出,但不想等到复制完成。所以我们使用 go func 和 闭包,然后有一个 for 循环,它读取输入值并写入输出,Go 中的 for range 子句将耗尽 channel。它一直运行直到 channel 为空,然后退出。所以这一小段代码会自动耗尽 channel。因为在后台运行,所以你不需要等待它。这是一个小小的范例,但你知道它还不错,而且已经习惯了。
A simple load balancer

现在让我向您展示一个非常简单的 Load Balancer。如果有时间的话,我会给你看另一个例子。这个例子很简单,想象一下你有一大堆工作要完成。我们将它们抽象出来,将它们具体化为一个包含三个整数值的 Work 结构体,您需要对其执行一些操作。

worker 要做的是根据这些值执行一些计算。然后我在此处加入 Sleep,以保证我们考虑阻塞。因为 worker 可能会被阻塞的一定的时间。我们构造它的方式是让 worker 从 input channel 读取要做的工作,并通过 output channel 传递结果,它们是这个函数的参数。在循环中,遍历输入值,执行计算,sleep 一段任意长的时间,然后将响应传递给输出,传递给等待的任务,所以我们得操心阻塞。那一定很难,对吧,以下就是全部的解决方案。

之所以如此简单,是因为channel 以及它与语言的其他元素一起工作的方式,让您能够表达并发的东西,并很好地组合它们。做法是创建两个 channel, input channel 和 output channel,连接到 worker。 所有 worker 从 input channel 读取,然后传输到 output channel;然后启动任意数量的 worker。注意中间的 go 子句,所有 worker 都在并发运行,也许是并行运行;然后你开始另一项工作,如屏幕显示为这些 worker 创造大量的工作,然后在函数调用中挂起,接收大量的结果,即从 ouput channel 中按照结果完成的顺序读取其值。因为作业结构化的方式,不管是在一个处理器上运行还是在一千个处理器上运行,都会正确而完整地运行。任何人使用该资源都可以同样完成,系统已经为你做好了一切。如果你思考这个问题,它很微不足道。但实际上,在大多数语言中,如果没有并发性,很难简洁地编写。并发性使得做这种事情,可以非常紧凑。

更重要的是,它是隐式并行性的(尽管不是,如果你不想,可以不必考虑该问题),它也能很好地扩展。没有同步或不同步。worker 数量可能是一个巨大的数字,而且它仍然可以高效地工作,因此并发工具使得为较大问题构建此类解决方案变得很容易。

还要注意,没有锁了,没有互斥锁了,所有这些都是在考虑旧的并发模型时需要考虑的,新模型没有了,你看不到它们的存在。然而,一个正确的无锁的并发、并行算法,一定很好,对吧?

但这太容易了,我们有时间看一个更难的。
Load balancer
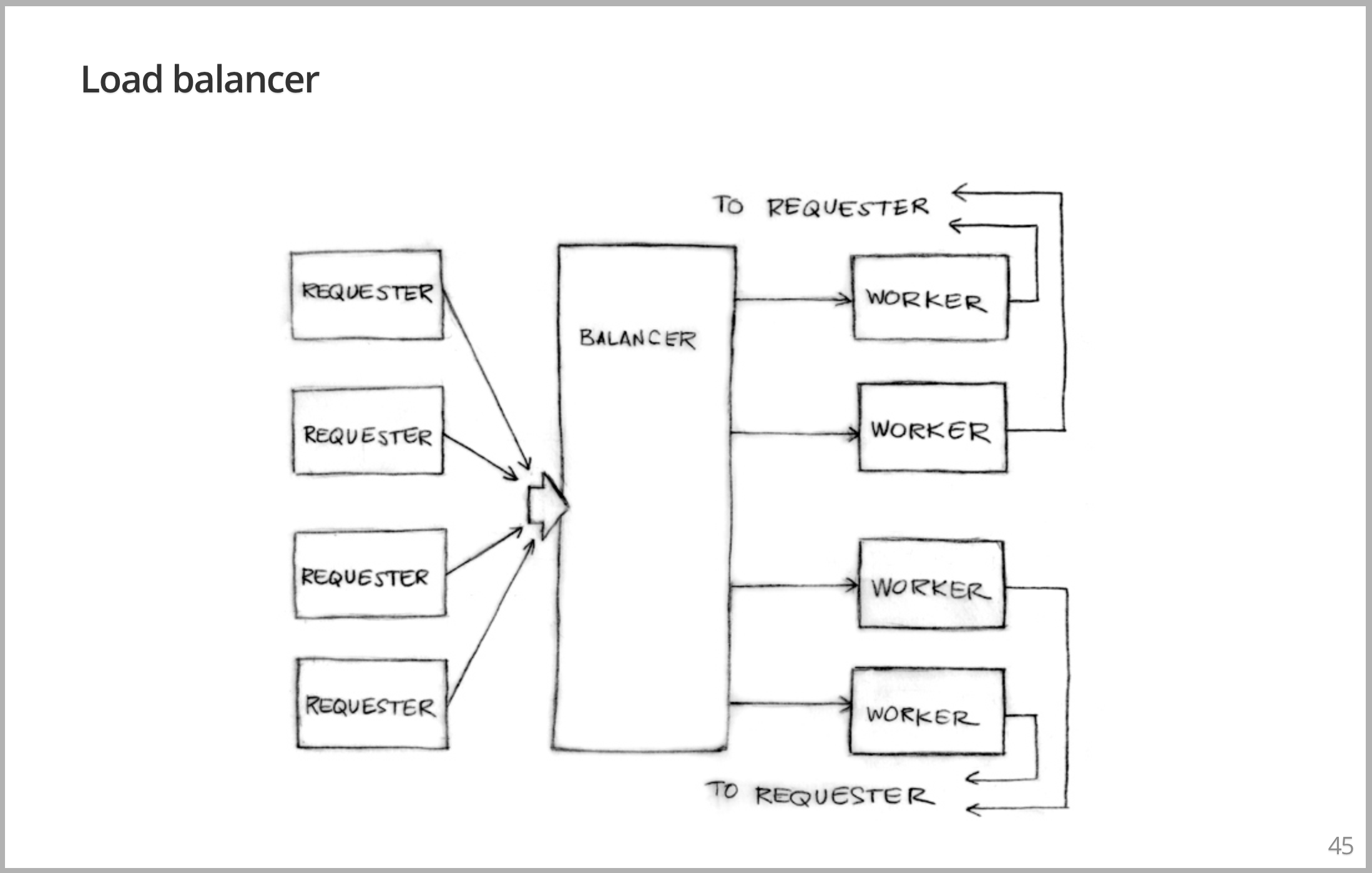
此例子有点棘手,相同的基本概念,但做的事情更符合现实。假设我们要写一个 Loader Balancer,有一堆 Requester 生成实际的工作,有一堆工作任务。希望将所有这些 Requester 的工作负载分配给任意数量的 Worker,并使其达到某种负载平衡,所以工作会分配给负荷最少的Worker。 所以你可以认为 Worker 们一次可能有大量的工作要做。他们可能同时要做的不止一个,可能有很多。因为有很多请求在处理,所以这会是一个很忙碌的系统。正如我演示的一样,它们也许是在同一台机器上。您也可以想象,其中一些线代表了正在进行适当负载均衡的网络连接,从结构上讲,我们的设计仍然是安全的。
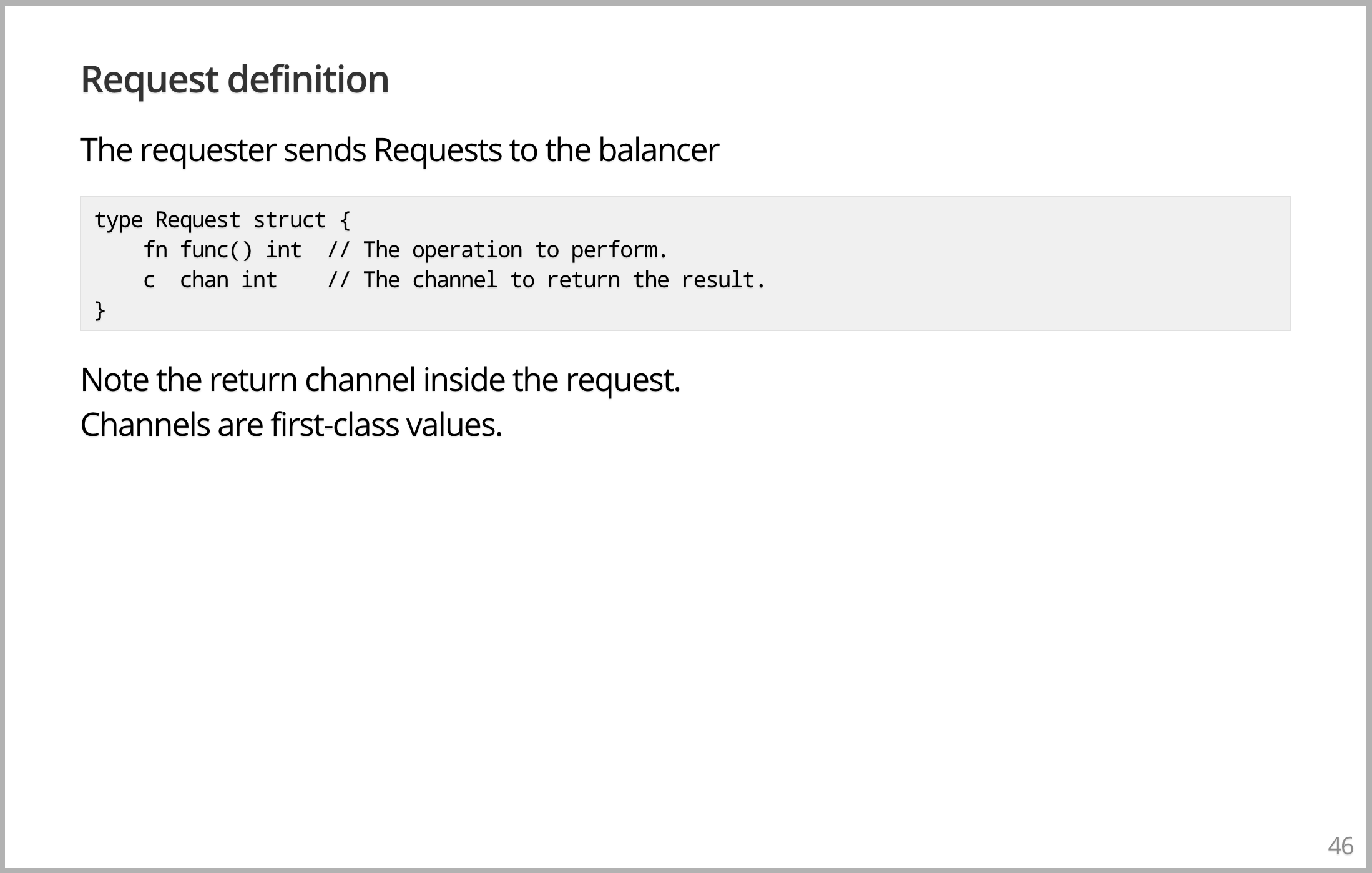
Request 现在看起来很不一样了。有一个任意数量函数的闭包,表示我们要做的计算;有一个 channel 可以返回结果。请注意,不像其他一些类似 Erlang 的语言,在 Go 中 channel 是 Reuqest 的一部分,channel 的概念就在那里,它是语言中 first-class 的东西,使得可以到处传递 channel。它在某种意义上类似于文件描述符,持有 channel 的对象就可以和其他对象通信,但没有 channel 的对象是做不到的。就好像打电话给别人,或者通过文件描述符传递文件一样,是一个相当有影响的概念。想法是,要发送一个需要计算的请求,它包含一个计算完成返回结果的 channel。

以下是一个虚构但能起到说明作用的版本的 Requester。所做的是,有一个请求可以进入的 channel,在这个 work channel 上生成要做的要做的任务;创建了一个 channel,并放入每个请求的内部,以便返回给我们答案。做了一些工作,使用 Sleep 代表(谁知道实际上在做什么)。你在 work channel 上发送一个带有用于计算的函数的请求对象,不管是什么,我不在乎;还有一个把答案发回去的 channel;然后你在那个 channel 等待结果返回。一旦你得到结果,你可能得对结果做些什么。这段代码只是按照一定速度生成工作。它只是产生结果,但是通过使用 input 和 output channel 通信来实现的。
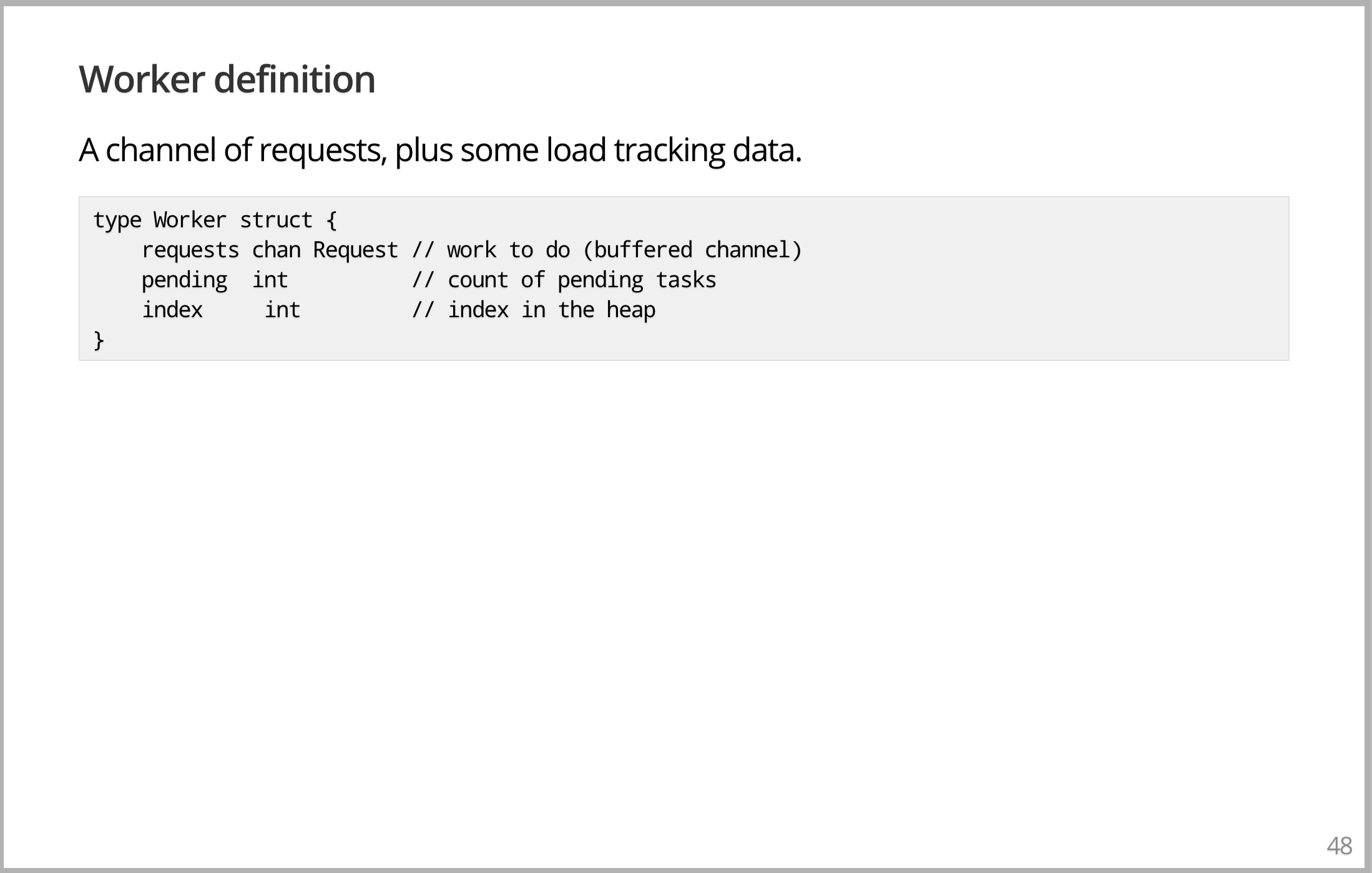
然后是 Worker,在前面的页面,记得么?有一些 Requester,右边的是Worker,它被提供给 balancer,是我最后要给你看的。Worker 拥有一个接收请求的 channel;一个等待任务的计数,Worker 拥有任务的数量代表其负载,它注定很忙;然后是一个 index,是堆结构的一部分,我们马上展示给你看。Worker 所做的就是从它的 Requester 那里接收工作。Request channel 是 Worker 对象的一部分。

调用 Worker 的函数,把请求传递给它,把从 Requester 生成的实际的函数通过均衡器传递给 Worker。Worker 计算答案,然后在 channel 上返回答案。请注意,与许多其他负载均衡架构不同,从 Worker 返回给 Requester 的 channel 不通过 Loader Balancer。一旦 Requester 和 Worker 建立连接,图中的“中介”就会消失,请求上的工作直接进行通信。因为在系统运行时,系统内部可以来回传递 channel。如果愿意,也可以在里面放一个 goroutine,在这里放一个 go 语句,然后在 Worker 上并行地处理所有的请求。如果这样做的话,一样会工作的很好,但这已经足够了。

Balancer 有点神奇,你需要一个 Worker 的 pool; 需要一些 Balancer 对象,以绑定一些方法到 Balancer。Balancer 包含一个 pool;一个 done channel,用以让 Worker 告诉 Loader Balancer 它已经完成了最近的计算。

所以 balance 很简单,它所做的只是永远执行一个 select 语句,等待做更多来自 Requester 的工作。在这种情况下,它会分发请求给负载最轻的 Worker;或者 Worker 告知,它已经完成计算,在这种情况下,可以通过更新数据结构表明 Worker 完成了它的任务。所以这只是一个简单的两路 select。然后,我们需要增加这两个函数,而要做到这一点,实际上要做的就是构造一个堆。

我跳过这些令人很兴奋的片段,你们已经知道什么意思。
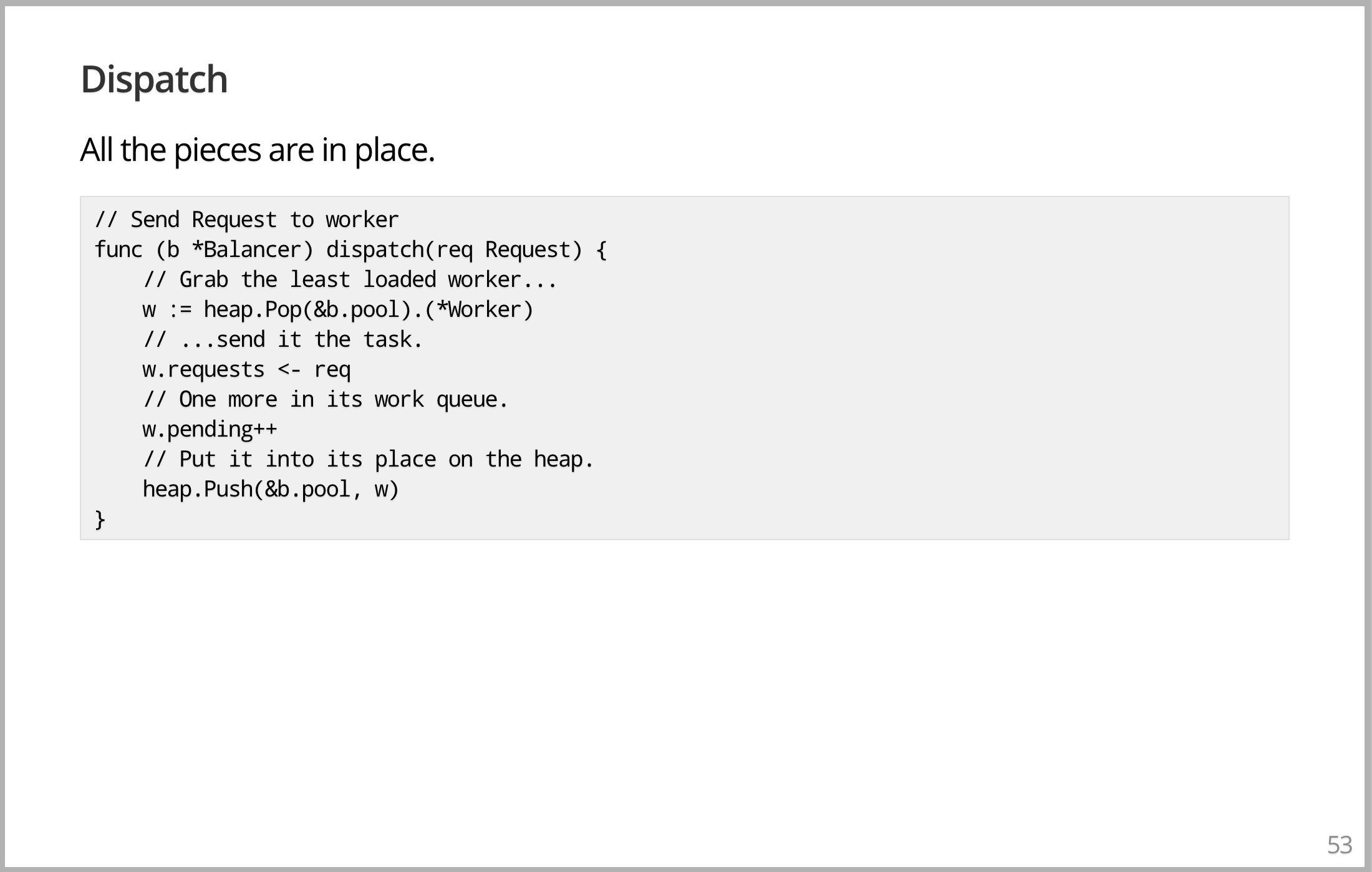
Dispatch, dispatch 要做的就是找到负载最少的 Worker,它是基于堆实现的一个标准优先级队列。所以你把负载最少的 Worker 从堆里取出来,通过将请求写入 request channel 来发送任务。因为增加了一个任务,需要增加负载,这会影响负载分布。然后你把它放回堆的同一个地方,就这样。你刚刚调度了它,并且在结构上进行了更新,这就是可执行代码行的内容。
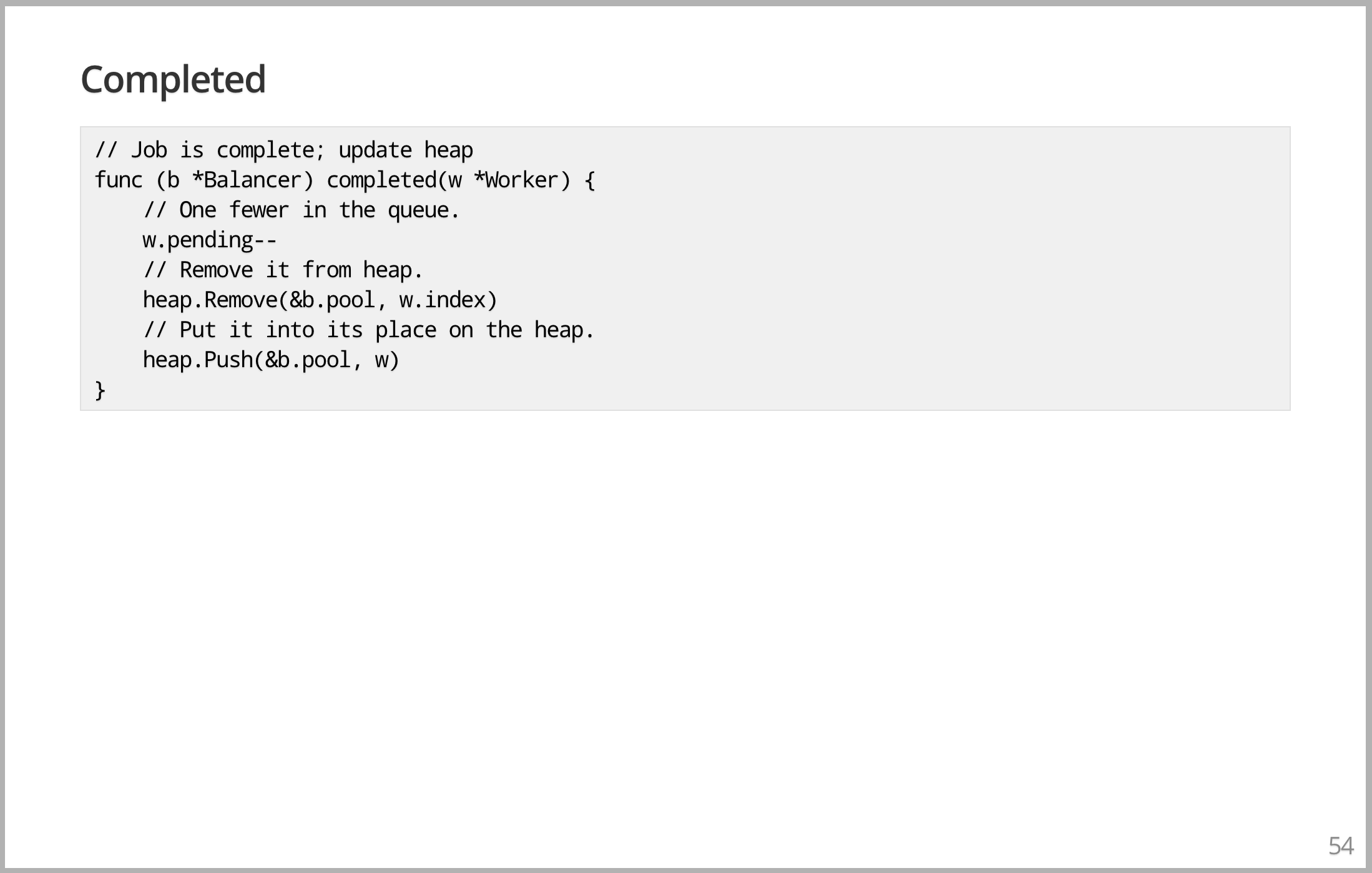
然后是 complete 的任务,也就是工作完成后,必须做一些相反的事情。 Worker 的队列中减少了一个任务,所以减少了它的等待计数。从堆里弹出 Worker,然后把它放回堆中,优先级队列会把它放回中它所属的位置,这是一个半现实的 Loader Balancer 的完整实现。此处的关键点是数据结构使用的是 channel 和 goroutine 来构造并发的东西。
Lesson

结果是可伸缩的,是正确的,很简单,没有显式的锁,而架构让它得以实现。因此,并发性使此例子的内在并行性成为可能。你可以运行这个程序,我有这个程序,它是可编译、可运行的,而且工作正常,负载均衡也做得很好。物体保持在均匀的负载下,按照模块量化,很不错。我从来没说过有多少 Worker,有多少问题。可能每个都有一个,另一个有数10个;或者每个都有一千,或者每个都有一百万,扩缩容仍然有效,并且仍然高效。
One more example

再举一个例子,这个例子有点令人惊讶,但它适合一张幻灯片就可以完成。
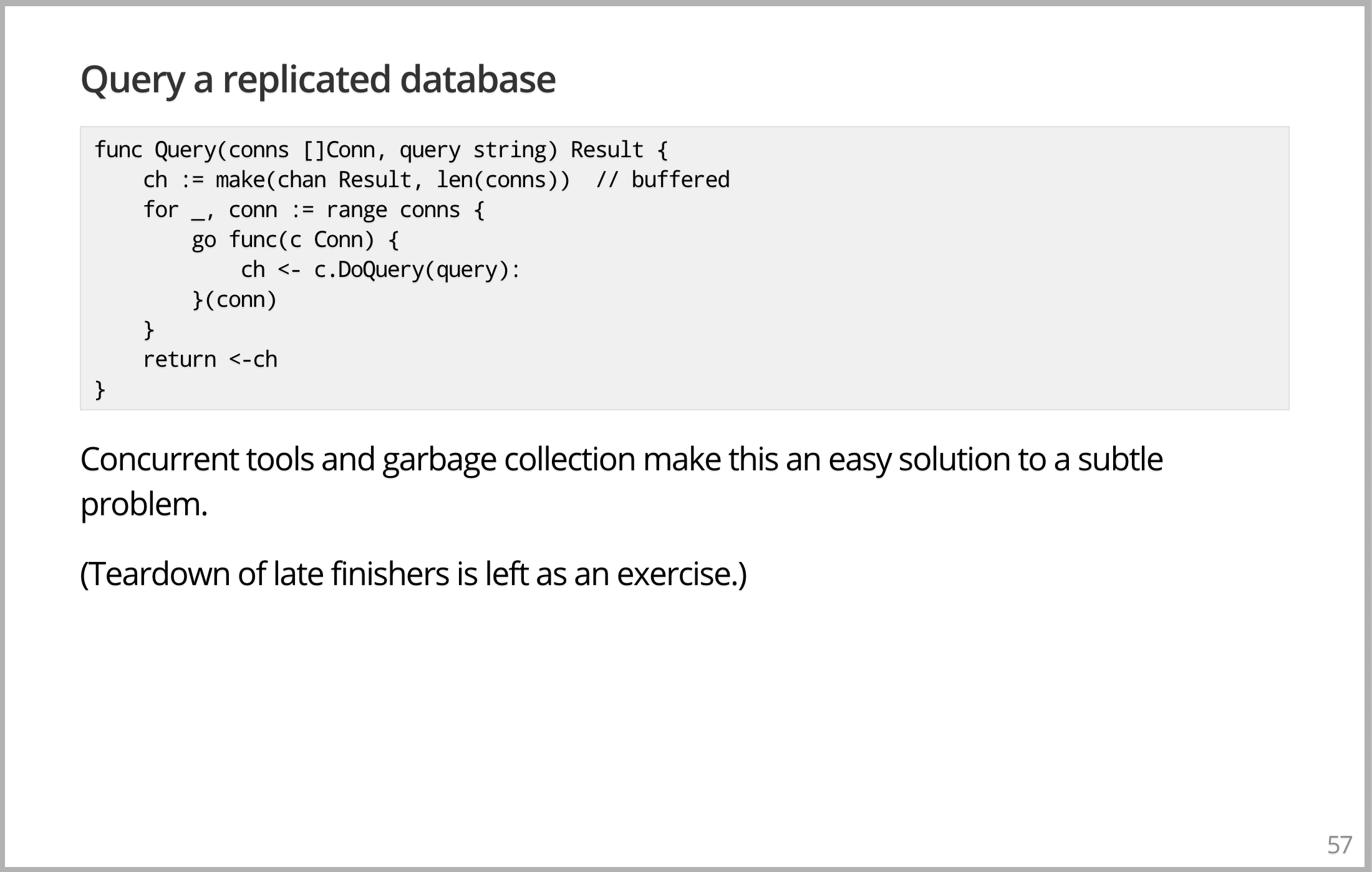
想象一下如何复制数据库,你得到了几个数据库,每个数据库中有相同的数据,谷歌称之为分片,称呼相同的实例。您要做的是向所有数据库传递一个请求,一个查询,并返回结果。结果会是一样的,你选择第一个应答请求来加快速度,因为首先要回来的是你想要的答案。如果其中一个坏了,断开了或者什么的,你不在乎。因为会有其他响应回来,这就是如何做到这一点。这就是它的全部实现。您有一些连接数组和一些要执行的查询,您创建一个 channel,该 channel 缓冲查询数据库中的元素数、副本内的副本数大小的内容,然后您只需在数据库的所有连接上执行。对于其中的每一个,您启动一个 goroutine 以将查询传递到该数据库,然后获取答案。但是通过这个 DoQuery 调用,将答案传递到唯一的 channel,这个 channel 保存所有请求的结果。然后,在你执行之后,所有的 goroutine 都只需在底部这行等待。我们等待第一个回到 channel 的请求,就是你想要的答案。返回它,就完成了。这看起来像个玩具,而且有点像。但这实际上是一个完全正确的实现,唯一缺少的是干净的回收。你想告诉那些还没回来的服务器关闭。当你已经得到答案,不再需要它们。你可以做,增加更多且合理的代码,但那就不适合放在幻灯片上了。所以我只想告诉你,在很多系统中,这是一个相当复杂的问题,但在这里,它只是自然地脱离了架构。因为你已经有了并发工具来表示一个相当大的复杂的分布式问题,它运行得非常好。
Conclusion

还剩五秒钟,很好。结论:并发性是强大的,但它不是并行性的,但它支持并行性,而且它使并行性变得容易。如果你明白了,那我就完成了我的工作。
For more information

如果你想看更多,这里有很多链接。golang.org 有关于 GO 你想知道的一切。有一份很好的历史 paper,链接如上。几年前我做了一个演讲,让我们真正开始开发Go语言,你可能会觉得很有趣。CMU 的 Bob Harper 有一篇非常不错的博客文章,叫做“并行不是并发”,这与“并发不是并行”的观点非常相似,虽然不完全一样。还有一些其他的东西,最令人惊讶的是,道格·马图尔(Doug Mathur),我在贝尔实验室(Bell Labs)的老板,所做的并行幂级数的工作,这是一篇了不起的论文。但如果你想与众不同的话。幻灯片上的最后一个链接是到另一种语言 sawzall,我从贝尔实验室(Bell Labs)来到谷歌后不久做的,这很了不起,因为它是不可思议的并行的语言,但它绝对没有并发性。现在我想你可能明白了这是可能的,所以非常感谢你的倾听和感谢 Hiroko 给我写信。我想是时候喝点什么了。
视频:https://vimeo.com/49718712
Slide:https://talks.golang.org/2012/waza.slide#1
源代码:https://github.com/golang/talks/tree/master/content/2012/waza
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/12-09-2019/concurrency-is-not-parallelism.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!