
背景
这是由C++ volatile引发的血案,血案第一部:了解CPU内核的细节。
Nehalem内核设计背景
Core架构具有一个移动计算的起源,它源自Banias Pentium M处理器,Pentium M处理器是以色列(Israel)的海法(Haifa)研究中心专门针对笔记本电脑的产品,特点是高效、低耗。Core架构之后迅速地成为Intel的主要架构,产品开始扩展到桌面乃至服务器产品线。Core架构古老的双核设计(4核是两个双核粘在一起,6核则是三个双核粘结)、过时的FSB总线以及没有充分为64位计算准备等等,让其无法获得很好的伸缩性,难以未来需要高性能多处理器需求的企业级市场。
Intel对Core架构作出了改动,首先它将原来的架构扩展为原生4核(甚至6核、8核)设计,并为多核的需要准备了新的总线QPI来满足巨大的带宽需求,结果就是Nehalem内核。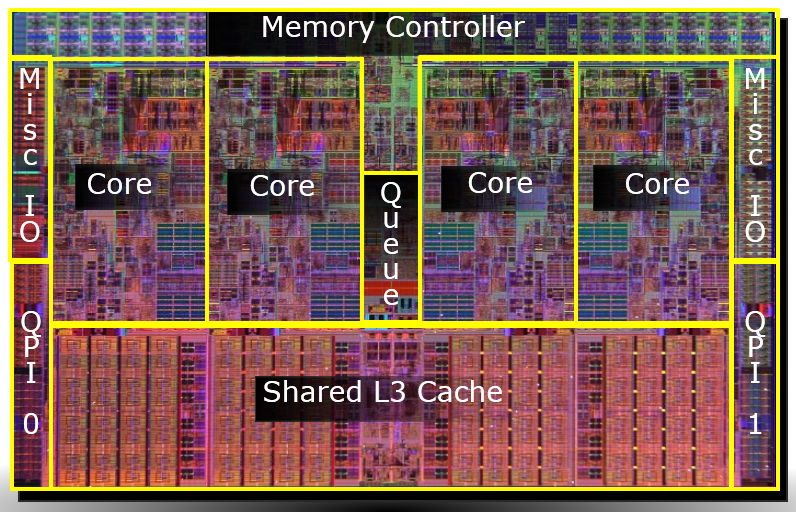
4核心Nehalem处理器架构
核心:功能区间划分
Nehalem是一款OOOE(Out of Order Execute)乱序执行的Superscaler超标量x86处理器。超标量的意思就是多个执行单元,可以同时执行多条没有相互依赖性的指令,从而达到提升ILP(Instruction Level Parallelism)指令级并行化的目的。乱序执行是指在多个执行单元的超标量设计当中,一系列的执行单元可以同时运行一些没有数据关联性的若干指令,只有需要等待其他指令运算结果的数据会按照顺序执行,从而总体提升了运行效率。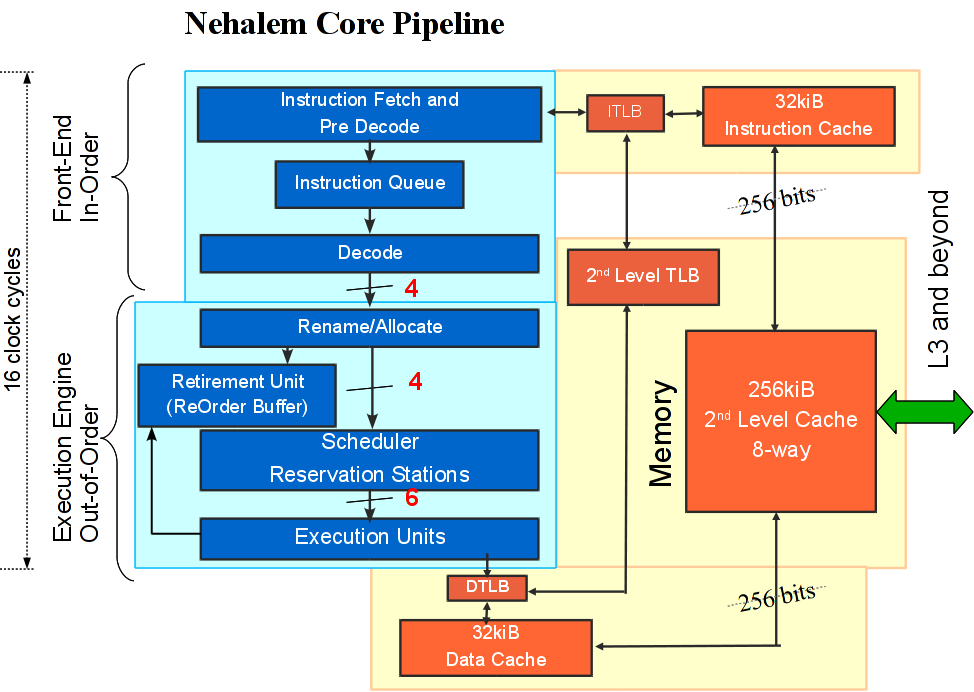
High-level diagram of a Nehalem core pipeline.
Core由以下部分组成:
in-order前端:拾取Intel64指令,使用四个解码器将指令解码为micro-ops,放入下游阶段的缓存中。
out-of-order执行引擎:输入数据和资源具备,每个时钟周期动态分配六个micro-ops到执行单元
in-order回退单元:确保micro-ops 的执行结果和结构状态(architected state )的更新符合源程序的顺序
以及多级缓存体系和地址转换资源
前端:指令拾取和解码
处理器在执行指令之前,必须先装载指令。指令会先保存在L1缓存的I-cache(Instruction-cache,L1D和L1I都是通过256bit的带宽连接到L2 Cache)指令缓存中,Nehalem的指令拾取单元通过访问 ITLB里的索引来从I-cache中读取指令。读取的指令做相应的 predecode 和 branch predication。结果送到指令队列 buffer(Instruction Queue)。再从 Instruction Queue fetch和decode,经过指令融和操作后,送调度单元分派指令。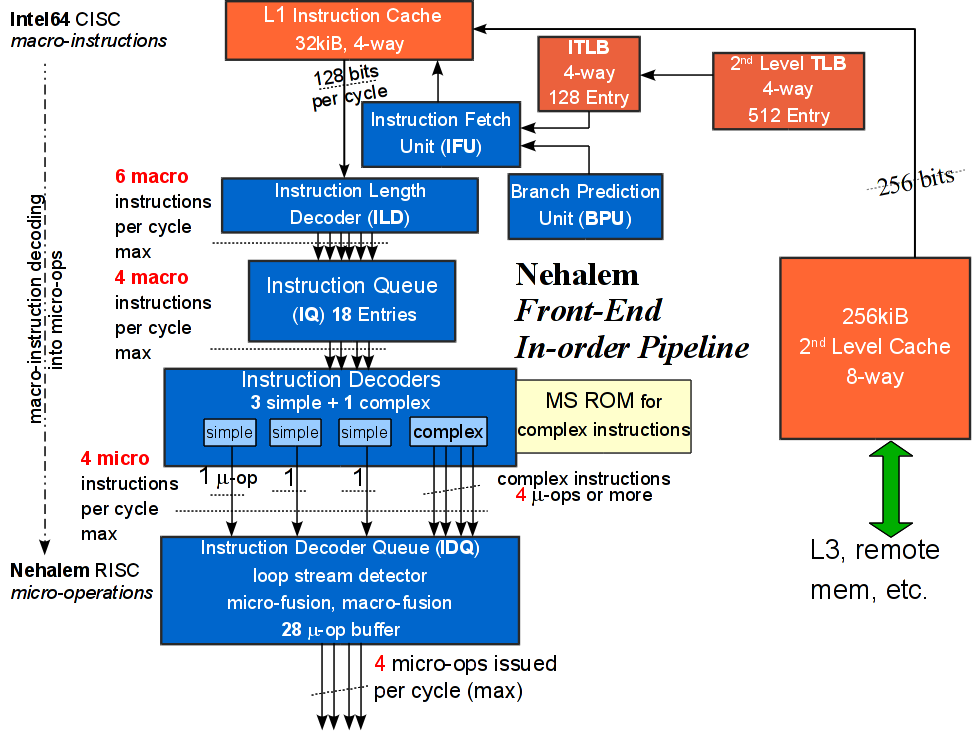
The Core Front-End: Instruction Fetch
指令拾取单元(IFU,Instruction Fetch Unit) 由ITLB ( Instruction Translation Lookaside Buffer)、instruction pre-fetcher、L1 i-cache(L1 instruction cache)和指令预解码器(instruction pre-decoder)组成。IFU每个时钟周期从L1 i-cache拾取16字节的指令到 Instruction Length Decoder。IFU使用ITLB来定位L1 i-cache和指令预取缓存中的16字节块。当命中缓存时,16字节的指令将会传输给instruction pre-decoder。
**分支预测单元(BPU,Branch-Prediction Unit)**在分支指令(如if then这样的语句)结果确定之前预取和处理后续指令,使得处理器执行预测路径上的指令时不“stalling”。
**指令预解码器(ILD or “Pre-Decoder”,Instruction Length Decoder)**接收Intel64 instructions ,确定指令长度、解码指令前缀、为解码器标注指令类型(如branch指令)。
**指令队列(Instruction Queue)**缓存预解码后的指令,并每个时钟周期传递5条指令给指令解码器(Instruction Decoder)。
在将指令充填到指令队列之后,就可以进行解码工作了,解码是类RISC(精简指令集或简单指令集)处理器导致的一项设计。处理器接受的是x86指令(CISC指令,复杂指令集),而在执行引擎内部执行的却不是x86指令,而是一条一条的类RISC指令,Intel称之为Micro Operation——micro-op,或者写为µ-op,一般用比较方便的写法来替代掉希腊字母:u-op或者uop。相对地,一条一条的x86指令就称之为Macro Operation,或macro-op。
RISC架构的特点就是指令长度相等,执行时间恒定(通常为一个时钟周期),因此处理器设计起来就很简单,可以通过深长的流水线达到很高的频率。和RISC相反,CISC指令的长度不固定,执行时间也不固定,因此Intel的RISC/CISC混合处理器架构就要通过解码器将x86指令翻译为uop,从而获得RISC架构的长处,提升内部执行效率。Nehalem有3个简单解码器加1个复杂解码器。简单解码器可以将一条x86指令翻译为一条uop,而复杂解码器则将一些特别的(单条)x86指令翻译为1~4条uops。在极少数的情况下,某些指令需要通过额外的可编程microcode解码器(MS ROM for Complex Decoder)解码为更多的uops。
指令解码单元(IDU, Instruction Decode Unit)解码预处理后的Intel64指令(macro-ops)为uop,并将uop放入下游的 instruction decoder queue (IDQ)。
对于一组uop,IDU会有一些优化措施,如:
循环流监测器(Loop Stream Detection):假如程序使用的循环段(如for..do/do..while等)少于28个uops,那么Nehalem就可以将这个循环保存起来,不再需要重新通过取指单元、分支预测操作,以及解码器,Core 2的LSD放在解码器前方,因此无法省下解码的工作。
Micro-Fusion: 将多条uops聚合用于降低uop的数量,提高Front-End的吞吐量和reorder buffer(ROB)的使用效率
执行引擎:乱序执行
执行引擎从上游的IDQ中选择micro-ops,动态调度分配给下游的执行单元执行。执行引擎是“out-of-order”的动态调度,超标量流水线允许micro-ops在代码语义不冲突的情况下并行的使用可用的执行单元。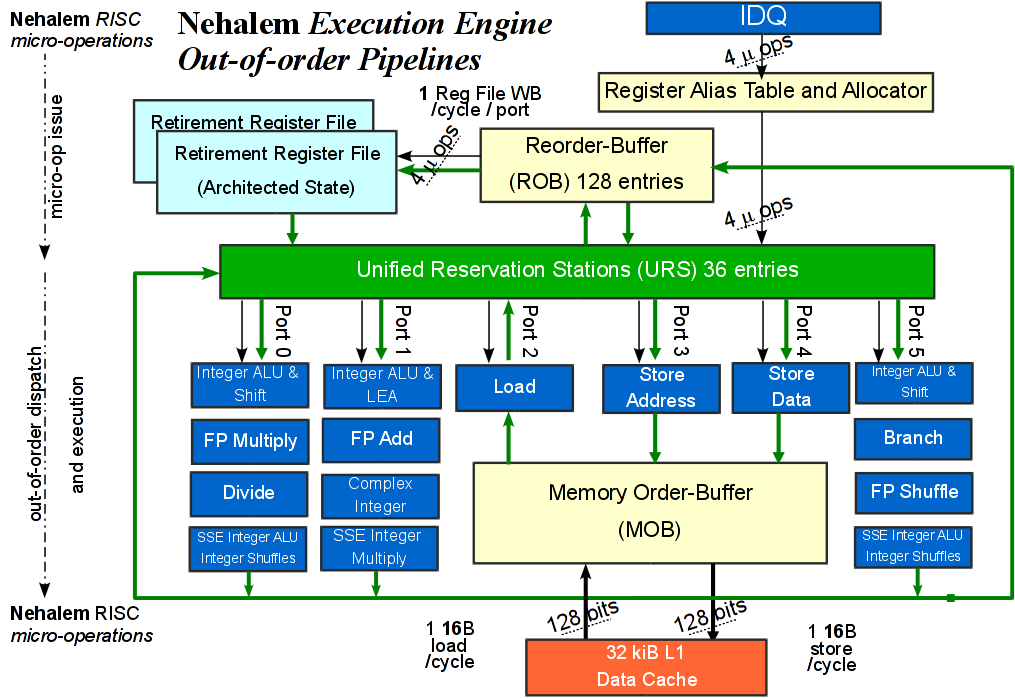
High-level diagram of a the out-of-order execution engine in the Nehalem core
执行引擎包含以下主要组件:
**Register Rename and Allocation Unit (RRAU)**:分配执行引擎的资源给IDQ中的micro-ops,并移动micro-ops给执行引擎。
**Reorder Buffer (ROB)**:追踪所有执行中的micro-ops。(没有结果的指令将在ROB等待)
Unified Reservation Station (URS):排队最大36条micro-ops直到操作资源ready,调度和分配ready的micro-ops到可用的执行单元。(没有数据的指令将在RS等待)
**Memory Order Buffer (MOB)**:支持推测、乱序load/store,确保正确的次序和数据写回内存
Execution Units and Operand Forwarding Network:每个时钟周期最多为一个micro-ops产生一个结果
在乱序执行架构中,不同的指令可能都会需要用到相同的通用寄存器(GPR,General Purpose Registers),为此Intel开始引入重命名寄存器(Rename Register),不同的指令可以通过具有名字相同但实际不同的寄存器来解决。
乱序执行从Allocator定位器开始,Allocator管理着RAT(Register Alias Table,寄存器别名表)、ROB(Re-Order Buffer,重排序缓冲区)和RRF(Retirement Register File,退回寄存器文件)。RAT将重命名的、虚拟的寄存器指向ROB或者RRF。RAT指向在ROB里面的最近的执行寄存器状态,或者指向RRF保存的最终的提交状态。当一条指令通过RAT发往下一个阶段确实执行的时候这条指令(包括寄存器状态在内)将被加入ROB队列的一端,在“乱序”之前,ROB的指令就已经确定了,指令并不是在ROB当中乱序挑选的(这在RS当中进行)。从执行单元返回的数据会将先前由调度器加入ROB的指令刷新数据部分并标志为结束(Finished),再经过其他检查通过后才能标志为完毕(Complete)。执行完毕的指令(包括寄存器状态)将从ROB队列的另一端移除(期间这些指令的数据可以被一些中间计算结果刷新),并提交寄存器状态。ROB担当的是流水线的最终阶段:一个指令的Retire回退单元;以及担当中间计算结果的缓冲区。提交状态的工作由Retirement Unit(回退单元)完成,它将确实完毕的指令包含的数据写入RRF(“确实”的意思是,非猜测执性、具备正确因果关系,程序可以见到的最终的寄存器状态)。RFF的数据最终先写入MOB(Memory Order Buffer,内存重排序缓冲区),再由MOB来完成写入L1D缓存。
猜测执行允许预先执行方向未定的分支指令。分支猜对了,其在ROB里产生的结果被标志为已结束,可以立即地被后继指令使用而不需要进行L1 Data Cache的Load操作。分支未能按照如期的情况进行,这时猜测的分支指令段将被清除,相应指令们的流水线阶段清空,对应的寄存器状态也就全都无效了。所以当指令和micro-ops在正确预测路径上才会发生状态的“Retirement”和“writeback”。Retirement处理满足以下两个条件:
1.与回退micro-op相关的所有micro-ops已经完毕”complete”,允许整条指令的Retirement。当一个指令的micro-ops的数量超大,填满回退窗口时,micro-ops可以回退。
2.正确预测路径上之前的指令的micro-ops已经发生回退。
这些保证处理器更新的状态与in-order执行的代码的micro-ops一致。
当之前的指令发生阻塞等待时,不会阻塞无依赖的新指令和micro-op执行。新指令的micro-ops将分配到执行单元,并且在ROB中等待执行完成。
结语
以上是指令在CPU内部的执行过程,从指令获取到计算结果回存。
敬请期待下篇《根据Nehalem架构了解CPU缓存体系》。
参考
解读 Intel® Microarchitecture
乱序执行引擎
ROB
inside nehalem
A High-Performance Nehalem iDataPlex Cluster and DDN S2A9990 Storage for Texas A&M University
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/06-01-2016/nehalem-arch.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!