
背景
随着内部重点服务接入的内容越来越多,维护各种内容的动态信息(例如:播放量,删除状态等)的成本越来越高。独立出一个内容服务成为很自然的选择。
内容提供方按照调用快慢依次:
- NoSQL数据库:耗时5ms以下
- BG内部服务:耗时10~20ms左右
- 外BG服务:耗时50ms+
由于内容经常会出现下线,而下线的内容一般在推荐结果中的位于头部,较大可能逃脱推荐服务的若干次截断,如果只在最终返回给用户的时候再进行过滤,就会出现部分类目的内容空白或者缺失。考虑到后端接口的性能,内容服务使用了二次过滤的方式来保证,因此服务提供了两个接口:
前置接口:粗粒度的状态过滤
后置接口:内容获取与状态再过滤
所谓粗粒度的过滤,就是可以容忍少量下线内容不被过滤掉,但是输入的数据量很大。再过滤则要求过滤掉所有下线内容,不过数据量只有前者的十分之一左右。根据以上分析就可以得到大致的架构,前置接口只查询缓存;后置接口依次按照缓存、KV、内部调用。而外部调用则通过异步更新的方式来保证。(由于内容在打开的时候,同样会进行内容有效性的检查,所以不涉及到缓存数据一致性)。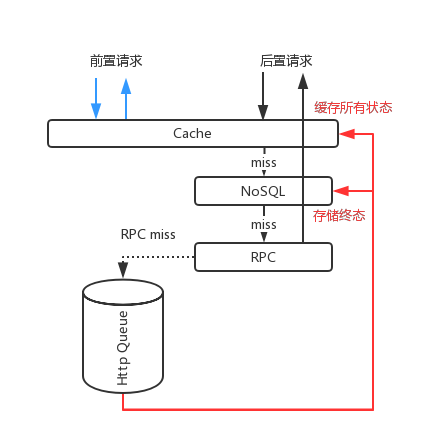
缓存访问分析
上图可见,我们可以得到以下结论
- 单机缓存查询:kw/m
所有的请求都会查询本地缓存,缓存查询次数每分钟会有数亿次。以十台机器算,每台机器每分钟有kw级的查询,10w+/m写入。 - 缓存淘汰算法、加锁方式影响巨大
缓存的空间是有限的,缓存更新需要合适的淘汰机制,而共享数据淘汰则需要添加锁。
第一版:LRU缓存
服务重构、完善监控、联调、灰度上线,Leader给的时间只有一周,所以缓存直接使用部门LRU缓存组件。缓存实现是unordered_map + 链表 + 互斥锁
第二版:分桶LRU缓存+状态/内容分离
第一版快速上线之后,发现单机并发始终上不去,性能瓶颈在前置接口,更准确说是锁冲突。LRU缓存组件被广泛使用在我们的后台系统中,之所以之前没有遇到类似的问题,是因为之前缓存读写的QPS远小于当前的应用场景,锁冲突的概率也远小于当前场景。那么如何减少锁冲突呢?参考深入了解锁细节以及我们的业务,可能有的选择是:
- 减少锁请求频率:批量读写代替单个读写
批量读写的问题也很明显,意味着临界区内的时间大大加长。持有锁的时间越长,锁冲突的几率越大,效果难说。
- 分离/分拆锁:将缓存分段,每段使用一个锁
效果明显,值得实施。
- 替代独占锁:使用自旋锁/读写锁代替独占锁
- 考虑使用LRU缓存的场景,对于内容缓存更新使用LRU没有问题。但对于状态数据等需要强制过期淘汰的数据来说,更合适的缓存更新的策略其实是FIFO。所以可以考虑内容和状态分开缓存。FIFO由于读数据不需要更新状态,可以使用读写锁代替独占锁
- 由于线程切换导致的代价详细位置,所以LRU使用自旋锁代替互斥锁,带来的收益以及付出的CPU代价,难以简单评估。
因此,第二版我们使用:“分桶LRU缓存” + **”状态/内容分离”**来进行优化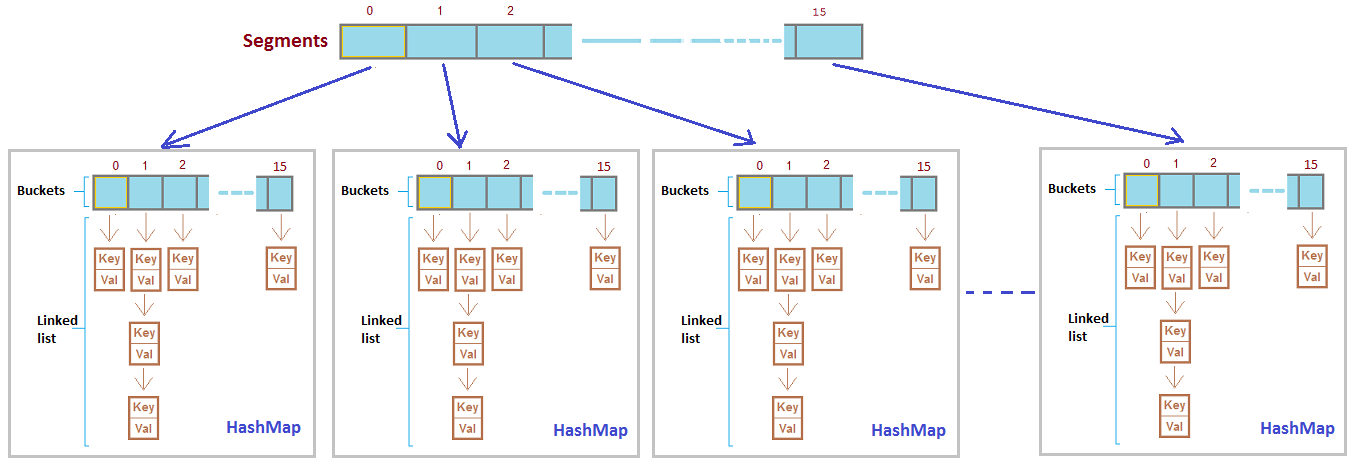
第三版:内存拷贝和对象析构优化
做完以上优化,使用perf工具跑下服务的性能。通过火焰图发现,由于单次请求查询数百条数据,会涉及到多次的对象创建和析构:
创建对象->【 拷贝放入缓存】-> 原对象析构
【缓存拷贝取出数据(对象过期析构)】 -> 返回对象析构
备注:【】临界区
而且对象的拷贝发生在临界区内,直接影响了持有锁的时间,而这些拷贝都可以通过share_ptr来避免,而过期对象的析构也可以通过异步处理来优化,这样大大减少了持有锁的时间,明显降低了锁冲突的概率。
总结
通过以上优化服务的并发成倍提升,耗时降低为第一版的一半,相同QPS CPU消耗降低三分之一,锁优化为缓存强依赖的服务带来明显收益。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/05-04-2018/lock-practice.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!