
背景
在业务新上线,或者业务做活动,压测成为必不可少的一步。但是很多开发对如何做好服务压测并没有特别系统的了解,这篇文章的目的是为了解释清楚单机服务压测的目的、做法、误区,帮助大家更好地达成压测的目的
压测的目的是什么?
- 检查性能瓶颈
服务的处理能力取决于资源中瓶颈最低的那个—木桶理论。我们并不总是对自己的服务这么自信,压测能够帮我们了解清楚在高压情况下的表现,发现隐藏的问题。
- 单机处理能力(QPS)
硬件影响了服务性,但处理能力跟硬件的关系有的时候并不是线性的,CPU从2核增加到4核,服务的能力并不一定会提高两倍。
- 容量规划的需要:什么系统,什么时候,需要多少服务器。
服务的责任人能够清晰的知道:什么时候该加机器、什么时候应该减机器?双11等大促场景需要准备多少机器,既能保障系统稳定性、又能节约成本
缺少经验的开发,经常无法很好达成三个目标中的任何一个。后续的内容我们讲按照三个目标逐一讲述,压测中可能存在的误区
性能瓶颈分析
在分析服务性能平静的时候,一般使用perf工具来生成服务在压测时的火焰图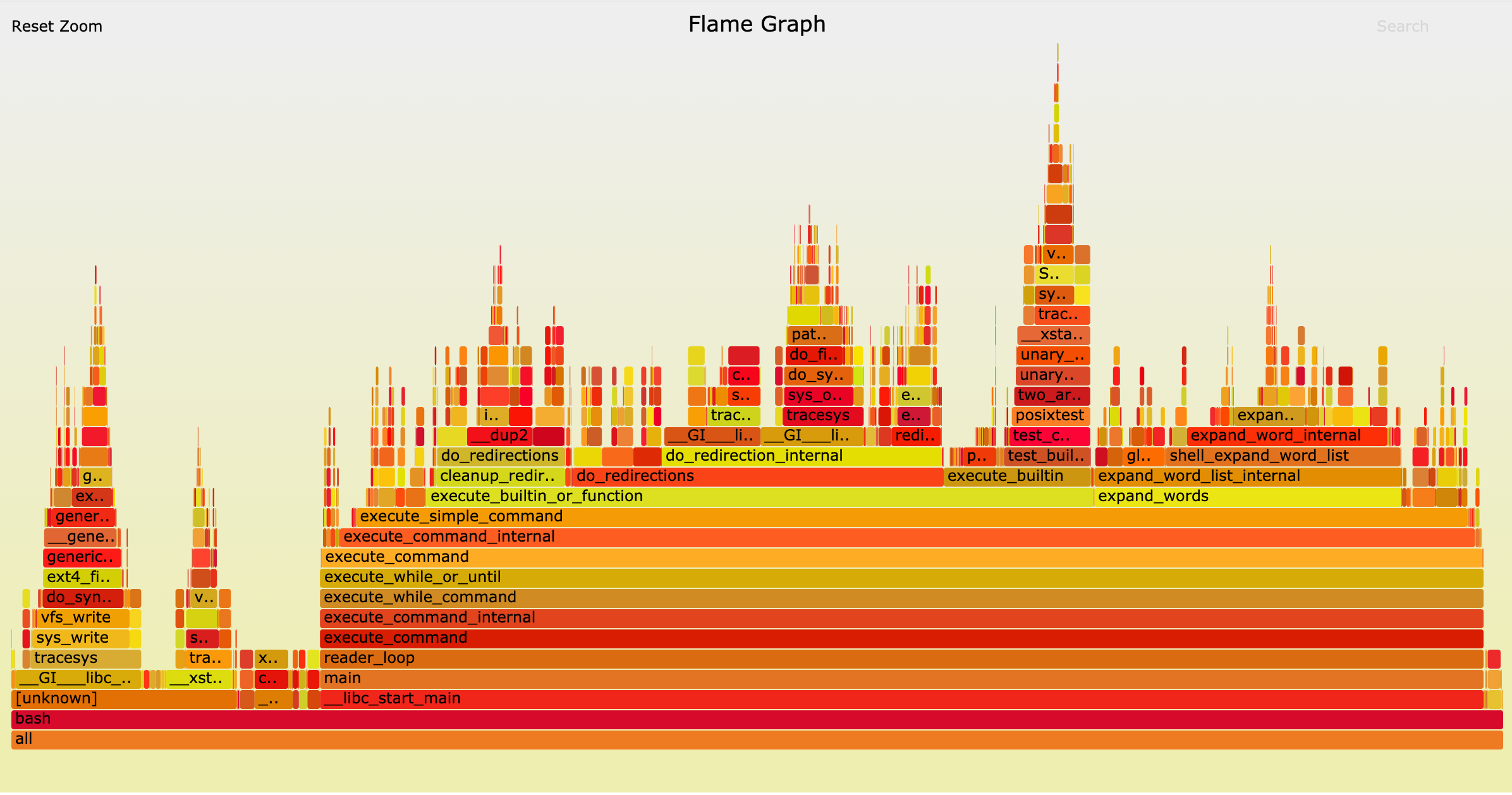
- y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
- x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题,需要特别留意和分析所占比例是否与预期相符。
误区
- 调用量不够,火焰图采样次数不足:采样次数会导致火焰图中函数占比有出入,导致火焰图缺少
- 分析不够:对于占用较多的函数,不能深入找出原因,得到合理的解释。
单机处理能力
一般来说服务的单机处理能力主要受设计方案、代码实现、硬件、第三方依赖共同决定。进入压测阶段,影响单机处理能力的,也就是硬件了,接下来我们了解下硬件
CPU
一般来说CPU核数越多,主频越高,服务的处理处理能力也就越高。当然,这里有个条件,就是每个CPU在处理的时候资源是独立的,否则当两个CPU同事都需要某一个资源时,其中一个就需要等待,直到资源闲置才能继续。因此,当服务中“锁”冲突严重时,CPU都浪费在线程/进程切换,CPU核数增加也无法带来处理性能的线性增长。此时就需要进行锁冲突优化,降低锁的粒度,甚至使用无锁服务。
内存
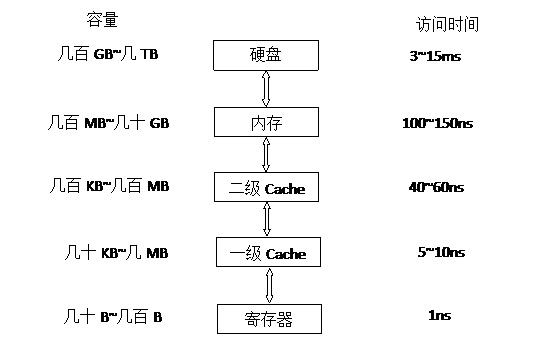
内存也是影响服务性能的一个重要因素。当内存充足的时候,内存分配和释放的代价会影响服务的性能。当服务不足的时候,会出现Swap分区的换入换出
磁盘IO
无论机械磁盘,还是固态硬盘读写,磁盘的读写速度与内存、CPU的速度都不在一个等级上。在一般的业务型服务中,经常会出现日志打印过多,磁盘IO瓶颈,导致服务处理能力与预期不符。
微信的服务在日志打印方面做得很好,所有的日志都直接打印共享内存,然后异步刷盘。业务就可以放心打日志,不用提心吊胆,随时炸弹爆炸。
误区
- 压测时不关心服务指标:导致缺少对系统基本层面的了解,一般监控内容包括响应时间、吞吐量、错误率、缓存命中率
- 不关注资源使用情况:包括CPU、内存、磁盘IO、网络吞吐、DB、Redis、MQ等
- 压测之后调整单机配置,期望单机性能得到线性增长
容量规划
很多开发在做完压测之后,对容量的准备和预估还是没有概念的,不知道多少容量能支撑整个系统。随着流量增加,期望加机器解决所有的问题。最后往往是所有的期望,全都化作失望。毕竟服务本身的处理能力,不仅取决于服务的性能,还取决于依赖的第三方服务处理能力,例如,Redis单机处理能力是10w QPS,如果有一个key的访问QPS到达瓶颈,服务的扩展再多的机器也是无济于事。
容量规划怎么做?
- 流量预估:通过历史数据(或者结合业务和时间)预估业务流量会有多大的系统调用量
- 容量评估:根据预估结果,计算服务需要分配多少机器
- 场景压测:针对重点业务场景,进行全局性的压测,根据压测结果再次调整。
参考链接:
- https://zhuanlan.zhihu.com/p/33923691
- https://github.com/brendangregg/FlameGraph
- https://huoding.com/2016/08/18/531
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/02-17-2019/stress-testing.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!